 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-NAS: Data Adapted Pruning for Efficient Neural Architecture Search
Paper and Code
Mar 27, 2020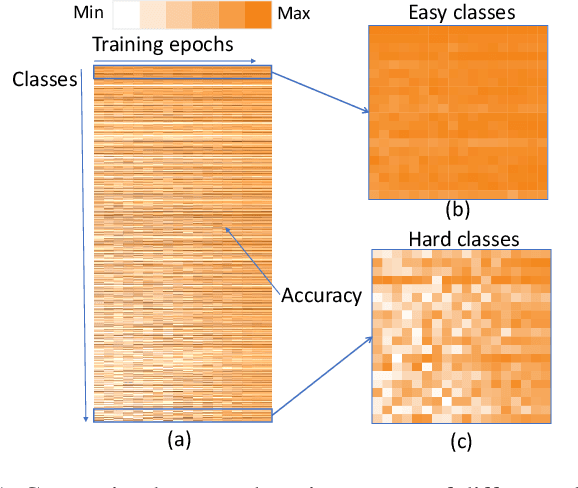
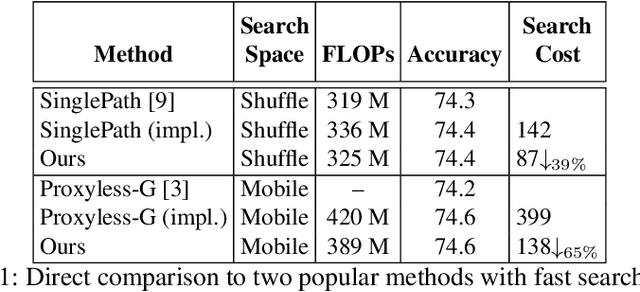
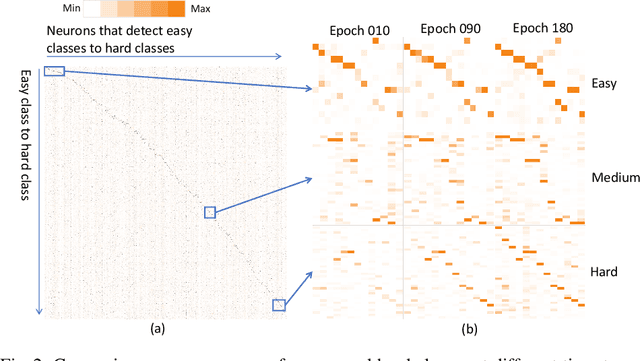
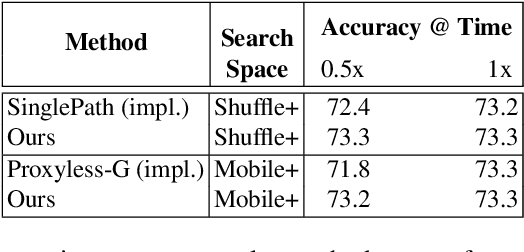
Efficient search is a core issue in Neural Architecture Search (NAS). It is difficult for conventional NAS algorithms to directly search the architectures on large-scale tasks like ImageNet. In general, the cost of GPU hours for NAS grows with regard to training dataset size and candidate set size. One common way is searching on a smaller proxy dataset (e.g., CIFAR-10) and then transferring to the target task (e.g., ImageNet). These architectures optimized on proxy data are not guaranteed to be optimal on the target task. Another common way is learning with a smaller candidate set, which may require expert knowledge and indeed betrays the essence of NAS. In this paper, we present DA-NAS that can directly search the architecture for large-scale target tasks while allowing a large candidate set in a more efficient manner. Our method is based on an interesting observation that the learning speed for blocks in deep neural networks is related to the difficulty of recognizing distinct categories. We carefully design a progressive data adapted pruning strategy for efficient architecture search. It will quickly trim low performed blocks on a subset of target dataset (e.g., easy classes), and then gradually find the best blocks on the whole target dataset. At this time, the original candidate set becomes as compact as possible, providing a faster search in the target task. Experiments on ImageNet verify the effectiveness of our approach. It is 2x faster than previous methods while the accuracy is currently state-of-the-art, at 76.2% under small FLOPs constraint. It supports an argument search space (i.e., more candidate blocks) to efficiently search the best-performing architecture.