 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Loss Functions in a Discriminative Space for Video Restoration
Paper and Code
Mar 20, 2020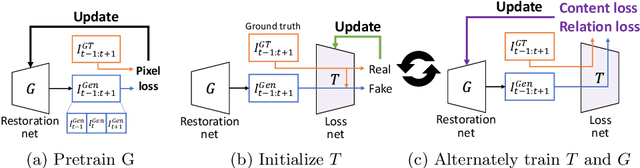
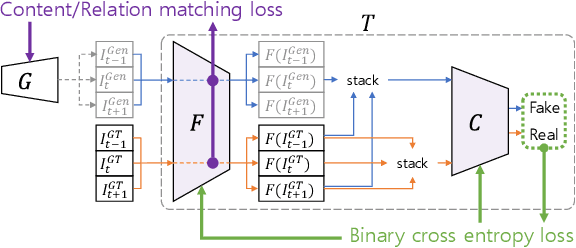

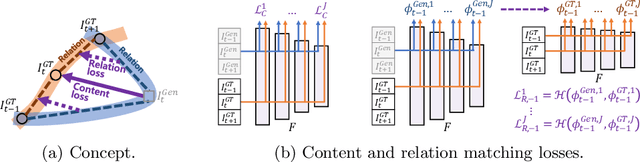
With more advanced deep network architectures and learning schemes such as GANs, the performance of video restoration algorithms has greatly improved recently. Meanwhile, the loss functions for optimizing deep neural networks remain relatively unchanged. To this end, we propose a new framework for building effective loss functions by learning a discriminative space specific to a video restoration task. Our framework is similar to GANs in that we iteratively train two networks - a generator and a loss network. The generator learns to restore videos in a supervised fashion, by following ground truth features through the feature matching in the discriminative space learned by the loss network. In addition, we also introduce a new relation loss in order to maintain the temporal consistency in output videos. Experiments on video superresolution and deblurring show that our method generates visually more pleasing videos with better quantitative perceptual metric values than the other state-of-the-art methods.