 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSASL: Saliency-Adaptive Sparsity Learning for Neural Network Acceleration
Paper and Code
Mar 12, 2020
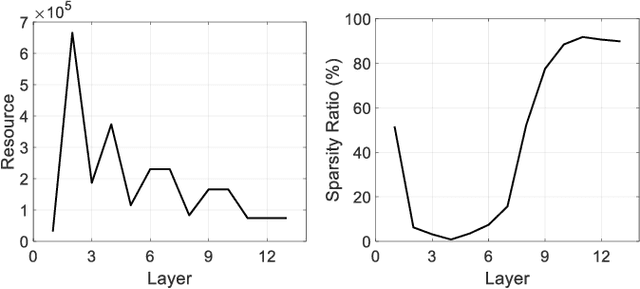

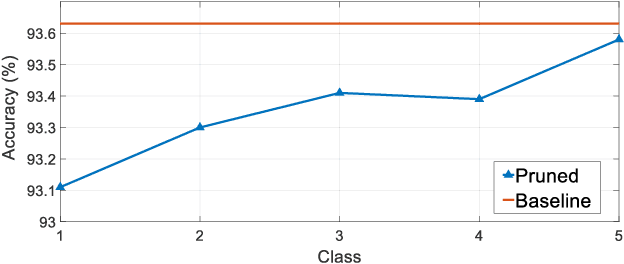
Accelerating the inference speed of CNNs is critical to their deployment in real-world applications. Among all the pruning approaches, those implementing a sparsity learning framework have shown to be effective as they learn and prune the models in an end-to-end data-driven manner. However, these works impose the same sparsity regularization on all filters indiscriminately, which can hardly result in an optimal structure-sparse network. In this paper, we propose a Saliency-Adaptive Sparsity Learning (SASL) approach for further optimization. A novel and effective estimation of each filter, i.e., saliency, is designed, which is measured from two aspects: the importance for the prediction performance and the consumed computational resources. During sparsity learning, the regularization strength is adjusted according to the saliency, so our optimized format can better preserve the prediction performance while zeroing out more computation-heavy filters. The calculation for saliency introduces minimum overhead to the training process, which means our SASL is very efficient. During the pruning phase, in order to optimize the proposed data-dependent criterion, a hard sample mining strategy is utilized, which shows higher effectiveness and efficiency. Extensive experiments demonstrate the superior performance of our method. Notably, on ILSVRC-2012 dataset, our approach can reduce 49.7% FLOPs of ResNet-50 with very negligible 0.39% top-1 and 0.05% top-5 accuracy degradation.