 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealizing Pixel-Level Semantic Learning in Complex Driving Scenes based on Only One Annotated Pixel per Class
Paper and Code
Mar 10, 2020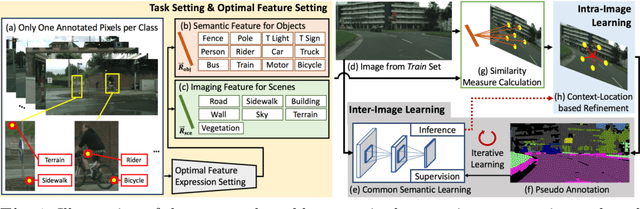


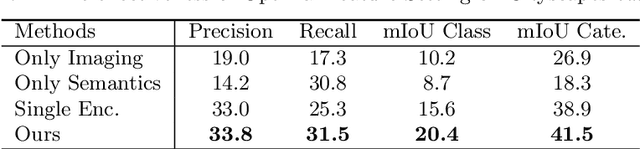
Semantic segmentation tasks based on weakly supervised condition have been put forward to achieve a lightweight labeling process. For simple images that only include a few categories, researches based on image-level annotations have achieved acceptable performance. However, when facing complex scenes, since image contains a large amount of classes, it becomes difficult to learn visual appearance based on image tags. In this case, image-level annotations are not effective in providing information. Therefore, we set up a new task in which only one annotated pixel is provided for each category. Based on the more lightweight and informative condition, a three step process is built for pseudo labels generation, which progressively implement optimal feature representation for each category, image inference and context-location based refinement. In particular, since high-level semantics and low-level imaging feature have different discriminative ability for each class under driving scenes, we divide each category into "object" or "scene" and then provide different operations for the two types separately. Further, an alternate iterative structure is established to gradually improve segmentation performance, which combines CNN-based inter-image common semantic learning and imaging prior based intra-image modification process. Experiments on Cityscapes dataset demonstrate that the proposed method provides a feasible way to solve weakly supervised semantic segmentation task under complex driving scenes.