 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOTS: Minimax Optimal Thompson Sampling
Paper and Code
Mar 03, 2020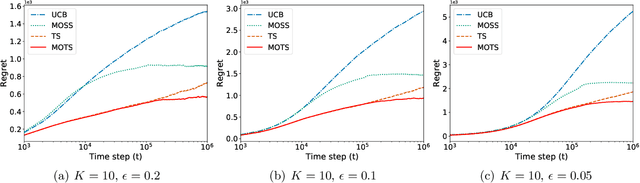
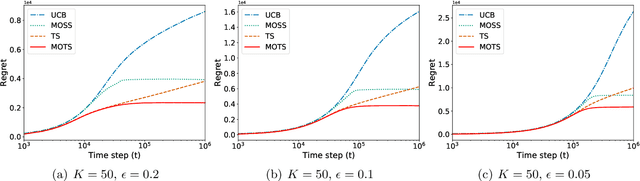
Thompson sampling is one of the most widely used algorithms for many online decision problems, due to its simplicity in implementation and superior empirical performance over other state-of-the-art methods. Despite its popularity and empirical success, it has remained an open problem whether Thompson sampling can achieve the minimax optimal regret $O(\sqrt{KT})$ for $K$-armed bandit problems, where $T$ is the total time horizon. In this paper, we solve this long open problem by proposing a new Thompson sampling algorithm called MOTS that adaptively truncates the sampling result of the chosen arm at each time step. We prove that this simple variant of Thompson sampling achieves the minimax optimal regret bound $O(\sqrt{KT})$ for finite time horizon $T$ and also the asymptotic optimal regret bound when $T$ grows to infinity as well. This is the first time that the minimax optimality of multi-armed bandit problems has been attained by Thompson sampling type of algorithms.