 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Root-Sign Activation Function
Paper and Code
Mar 01, 2020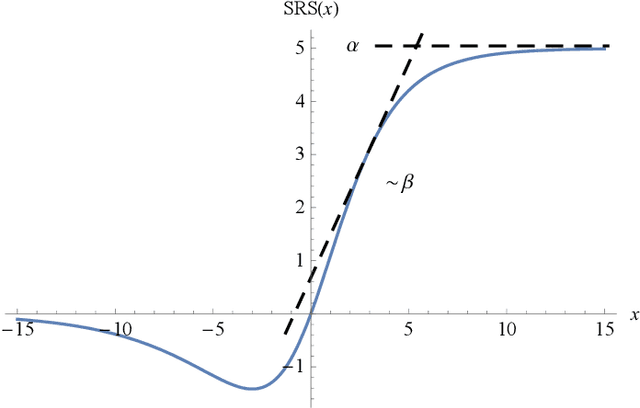
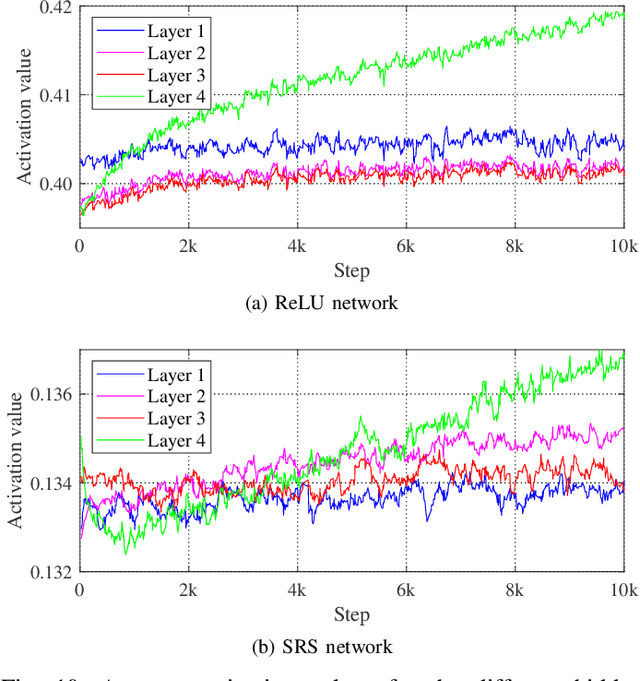
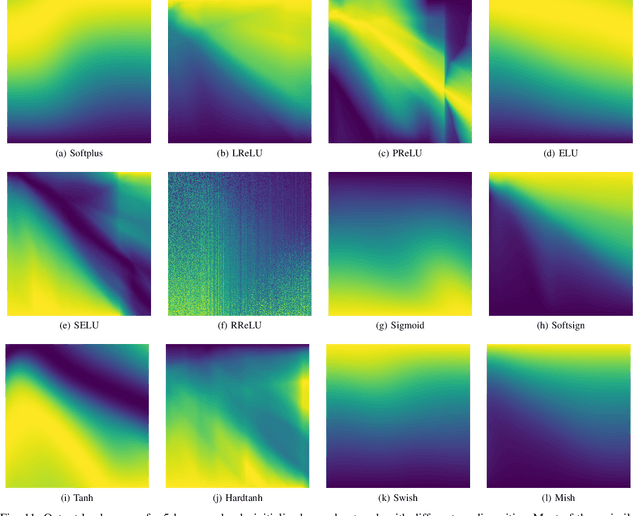
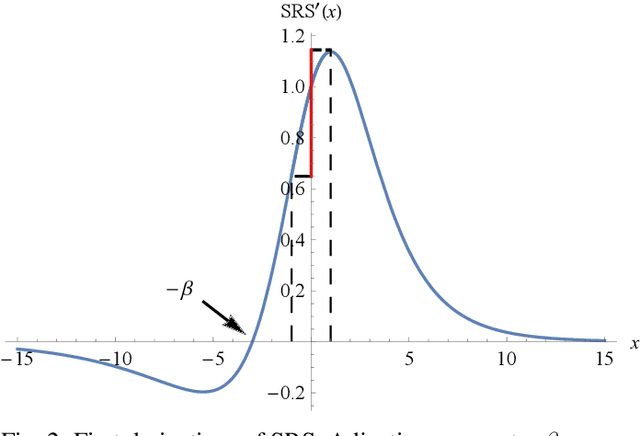
The choice of activation function in deep networks has a significant effect on the training dynamics and task performance. At present, the most effective and widely-used activation function is ReLU. However, because of the non-zero mean, negative missing and unbounded output, ReLU is at a potential disadvantage during optimization. To this end, we introduce a novel activation function to manage to overcome the above three challenges. The proposed nonlinearity, namely "Soft-Root-Sign" (SRS), is smooth, non-monotonic, and bounded. Notably, the bounded property of SRS distinguishes itself from most state-of-the-art activation functions. In contrast to ReLU, SRS can adaptively adjust the output by a pair of independent trainable parameters to capture negative information and provide zero-mean property, which leading not only to better generalization performance, but also to faster learning speed. It also avoids and rectifies the output distribution to be scattered in the non-negative real number space, making it more compatible with batch normalization (BN) and less sensitive to initialization. In experiments, we evaluated SRS on deep networks applied to a variety of tasks, including image classification, machine translation and generative modelling. Our SRS matches or exceeds models with ReLU and other state-of-the-art nonlinearities, showing that the proposed activation function is generalized and can achieve high performance across tasks. Ablation study further verified the compatibility with BN and self-adaptability for different initialization.