 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Contention Aware Scheduling of Multiple Deep Learning Training Jobs
Paper and Code
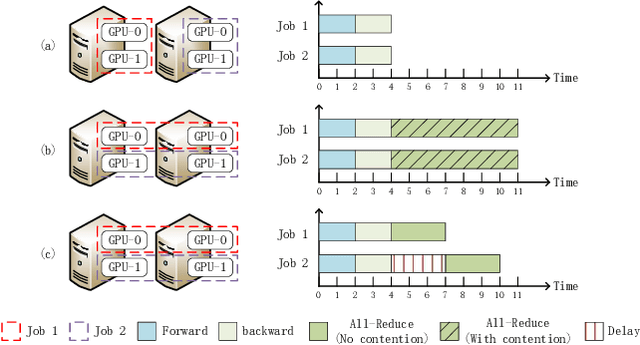
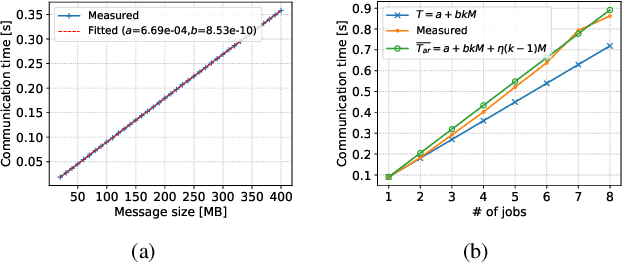
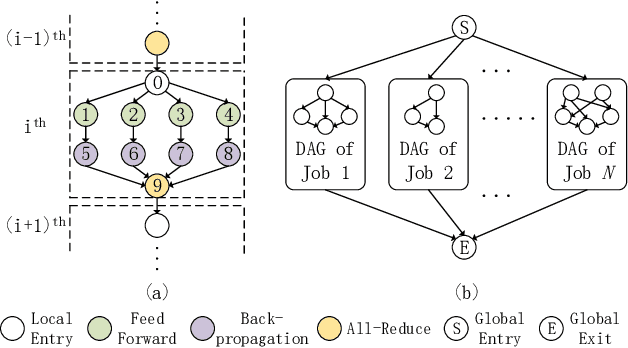
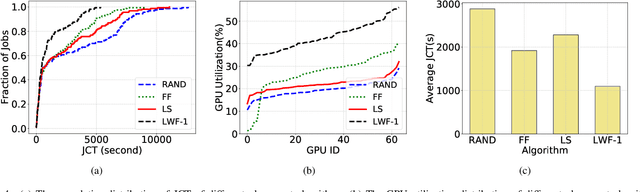
Distributed Deep Learning (DDL) has rapidly grown its popularity since it helps boost the training performance on high-performance GPU clusters. Efficient job scheduling is indispensable to maximize the overall performance of the cluster when training multiple jobs simultaneously. However, existing schedulers do not consider the communication contention of multiple communication tasks from different distributed training jobs, which could deteriorate the system performance and prolong the job completion time. In this paper, we first establish a new DDL job scheduling framework which organizes DDL jobs as Directed Acyclic Graphs (DAGs) and considers communication contention between nodes. We then propose an efficient algorithm, LWF-$\kappa$, to balance the GPU utilization and consolidate the allocated GPUs for each job. When scheduling those communication tasks, we observe that neither avoiding all the contention nor blindly accepting them is optimal to minimize the job completion time. We thus propose a provable algorithm, AdaDUAL, to efficiently schedule those communication tasks. Based on AdaDUAL, we finally propose Ada-SRSF for the DDL job scheduling problem. Simulations on a 64-GPU cluster connected with 10 Gbps Ethernet show that LWF-$\kappa$ achieves up to $1.59\times$ improvement over the classical first-fit algorithms. More importantly, Ada-SRSF reduces the average job completion time by $20.1\%$ and $36.7\%$, as compared to the SRSF(1) scheme (avoiding all the contention) and the SRSF(2) scheme (blindly accepting all of two-way communication contention) respectively.