 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Explore-then-Commit: Asymptotic Optimality and Beyond
Paper and Code
Feb 21, 2020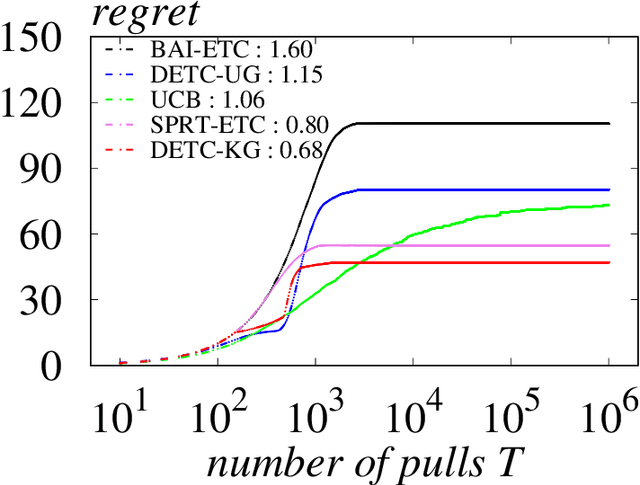
We study the two-armed bandit problem with subGaussian rewards. The explore-then-commit (ETC) strategy, which consists of an exploration phase followed by an exploitation phase, is one of the most widely used algorithms in a variety of online decision applications. Nevertheless, it has been shown in Garivier et al. (2016) that ETC is suboptimal in the asymptotic sense as the horizon grows, and thus, is worse than fully sequential strategies such as Upper Confidence Bound (UCB). In this paper, we argue that a variant of ETC algorithm can actually achieve the asymptotically optimal regret bounds for multi-armed bandit problems as UCB-type algorithms do. Specifically, we propose a double explore-then-commit (DETC) algorithm that has two exploration and exploitation phases. We prove that DETC achieves the asymptotically optimal regret bound as the time horizon goes to infinity. To our knowledge, DETC is the first non-fully-sequential algorithm that achieves such asymptotic optimality. In addition, we extend DETC to batched bandit problems, where (i) the exploration process is split into a small number of batches and (ii) the round complexity is of central interest. We prove that a batched version of DETC can achieve the asymptotic optimality with only constant round complexity. This is the first batched bandit algorithm that can attain asymptotic optimality in terms of both regret and round complexity.