 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoLayout: Amodal scene layout from a single image
Paper and Code
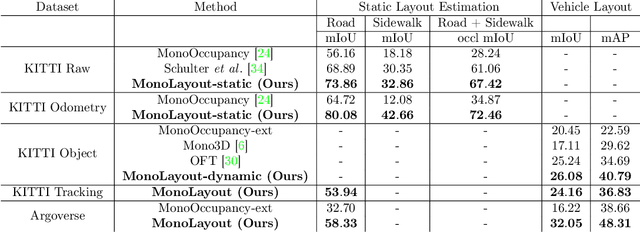
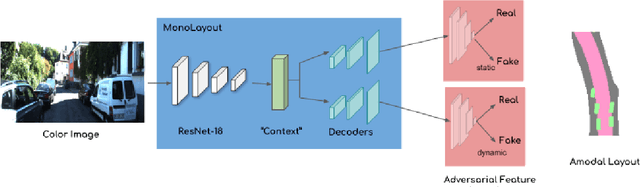
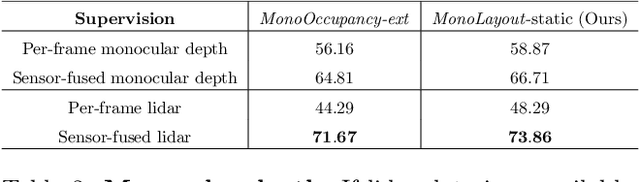
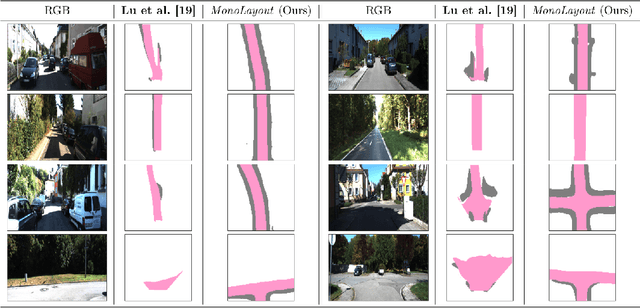
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .