 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Global Transparent Models from Local Contrastive Explanations
Paper and Code
Feb 19, 2020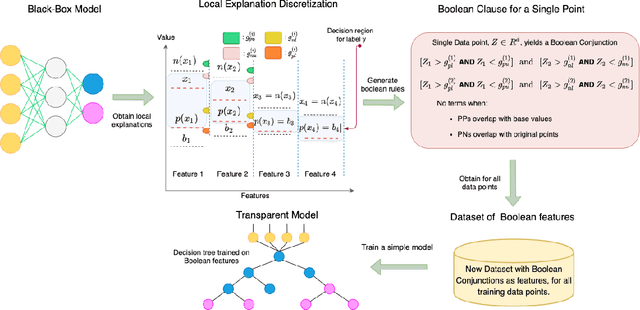
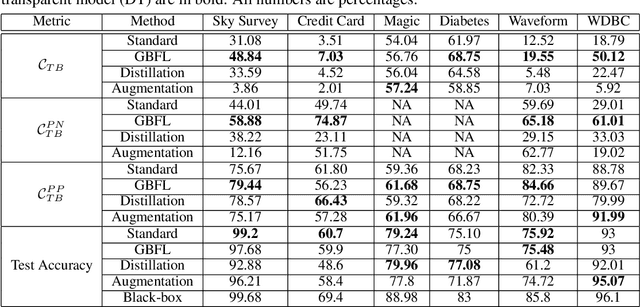
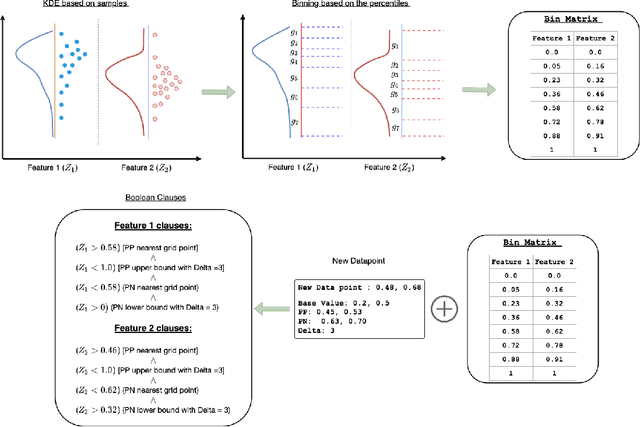
There is a rich and growing literature on producing local point wise contrastive/counterfactual explanations for complex models. These methods highlight what is important to justify the classification and/or produce a contrast point that alters the final classification. Other works try to build globally interpretable models like decision trees and rule lists directly by efficient model search using the data or by transferring information from a complex model using distillation-like methods. Although these interpretable global models can be useful, they may not be consistent with local explanations from a specific complex model of choice. In this work, we explore the question: Can we produce a transparent global model that is consistent with/derivable from local explanations? Based on a key insight we provide a novel method where every local contrastive/counterfactual explanation can be turned into a Boolean feature. These Boolean features are sparse conjunctions of binarized features. The dataset thus constructed is consistent with local explanations by design and one can train an interpretable model like a decision tree on it. We note that this approach strictly loses information due to reliance only on sparse local explanations, nonetheless, we demonstrate empirically that in many cases it can still be competitive with respect to the complex model's performance and also other methods that learn directly from the original dataset. Our approach also provides an avenue to benchmark local explanation methods in a quantitative manner.