 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning from Videos via Efficient Inter-Frame Attention
Paper and Code
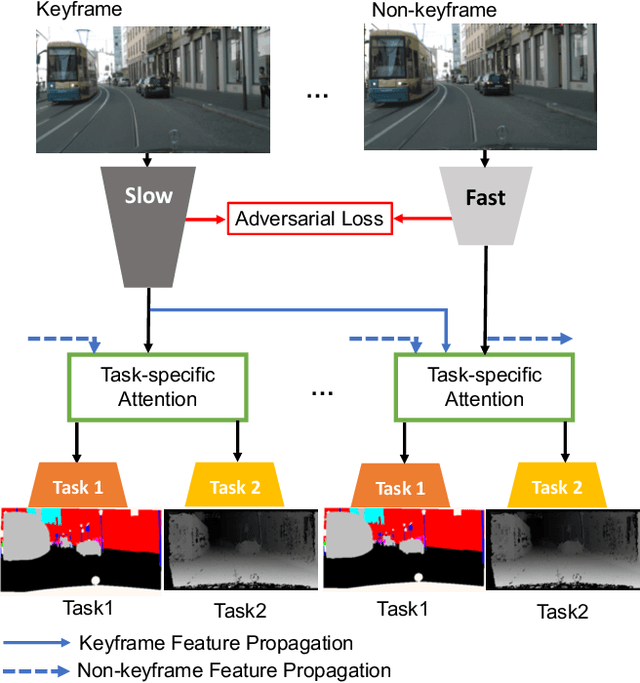
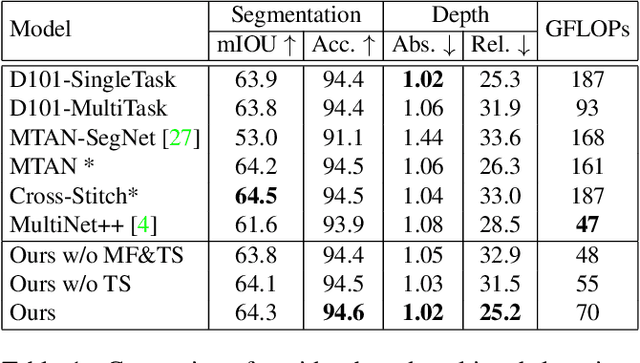
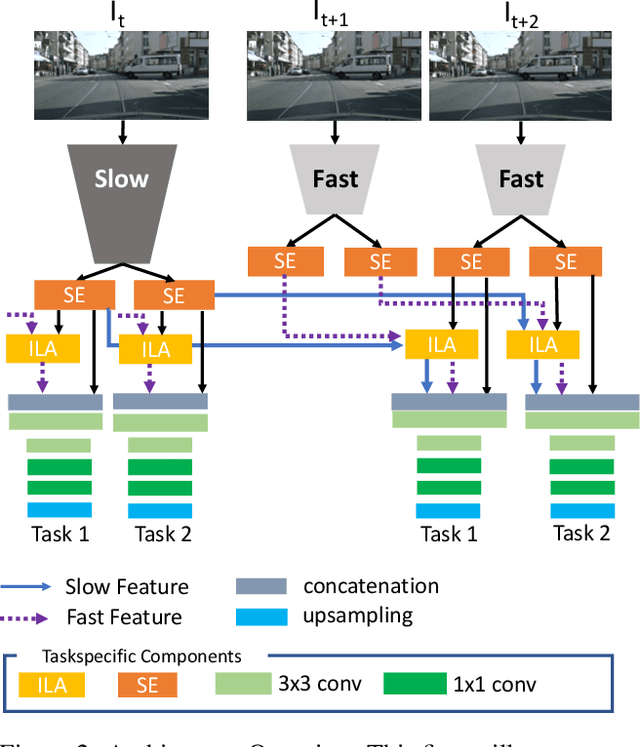
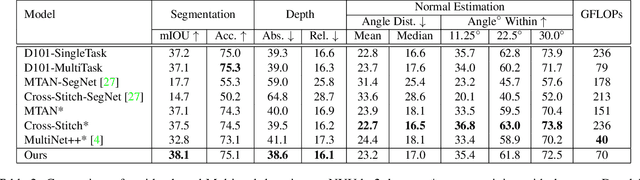
Prior work in multi-task learning has mainly focused on predictions on a single image. In this work, we present a new approach for multi-task learning from videos. Our approach contains a novel inter-frame attention module which allows learning of task-specific attention across frames. We embed the attention module in a "slow-fast" architecture, where the slower network runs on sparsely sampled keyframes and the lightweight shallow network runs on non-key frames at a high frame rate. We further propose an effective adversarial learning strategy to encourage the slow and fast network to learn similar features. The proposed architecture ensures low-latency multi-task learning while maintaining high quality prediction. Experiments show competitive accuracy compared to state-of-the-art on two multi-task learning benchmarks while reducing the number of floating point operations (FLOPs) by 70%. Meanwhile, our attention based feature propagation outperforms other feature propagation methods in accuracy by up to 90% reduction of FLOPs.