 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compare for Better Training and Evaluation of Open Domain Natural Language Generation Models
Paper and Code
Feb 12, 2020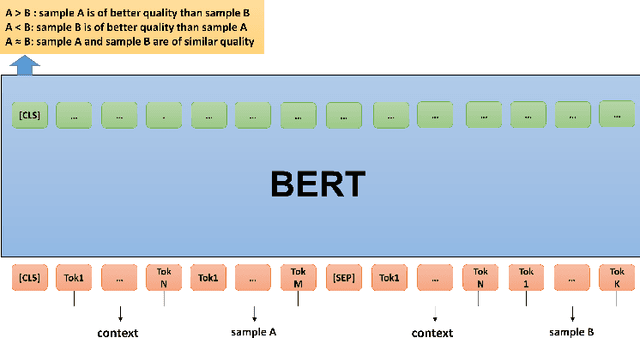
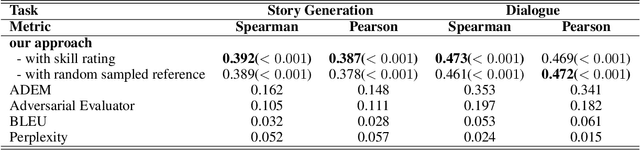
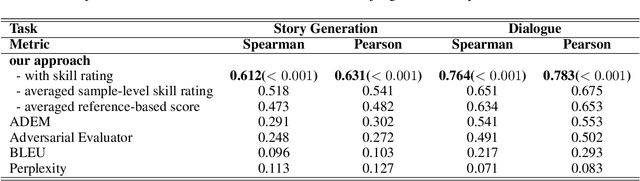
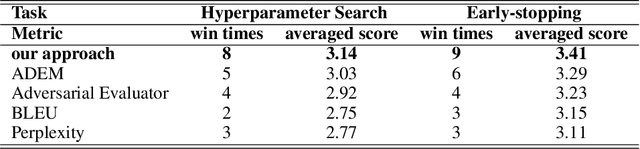
Automated evaluation of open domain natural language generation (NLG) models remains a challenge and widely used metrics such as BLEU and Perplexity can be misleading in some cases. In our paper, we propose to evaluate natural language generation models by learning to compare a pair of generated sentences by fine-tuning BERT, which has been shown to have good natural language understanding ability. We also propose to evaluate the model-level quality of NLG models with sample-level comparison results with skill rating system. While able to be trained in a fully self-supervised fashion, our model can be further fine-tuned with a little amount of human preference annotation to better imitate human judgment. In addition to evaluating trained models, we propose to apply our model as a performance indicator during training for better hyperparameter tuning and early-stopping. We evaluate our approach on both story generation and chit-chat dialogue response generation. Experimental results show that our model correlates better with human preference compared with previous automated evaluation approaches. Training with the proposed metric yields better performance in human evaluation, which further demonstrates the effectiveness of the proposed model.