 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-rational (implicit) choice: A unifying formalism for reward learning
Paper and Code
Feb 12, 2020
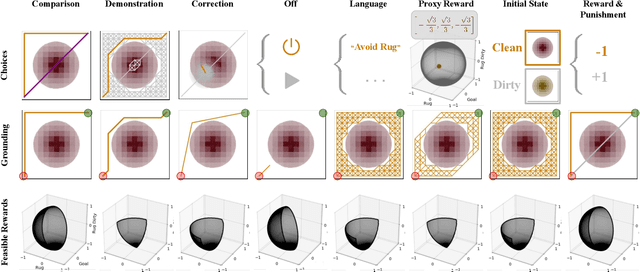

It is often difficult to hand-specify what the correct reward function is for a task, so researchers have instead aimed to learn reward functions from human behavior or feedback. The types of behavior interpreted as evidence of the reward function have expanded greatly in recent years. We've gone from demonstrations, to comparisons, to reading into the information leaked when the human is pushing the robot away or turning it off. And surely, there is more to come. How will a robot make sense of all these diverse types of behavior? Our key insight is that different types of behavior can be interpreted in a single unifying formalism - as a reward-rational choice that the human is making, often implicitly. The formalism offers both a unifying lens with which to view past work, as well as a recipe for interpreting new sources of information that are yet to be uncovered. We provide two examples to showcase this: interpreting a new feedback type, and reading into how the choice of feedback itself leaks information about the reward.