 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity-Aware Deep Learning for Automatic 4D Facial Expression Recognition
Paper and Code
Feb 08, 2020
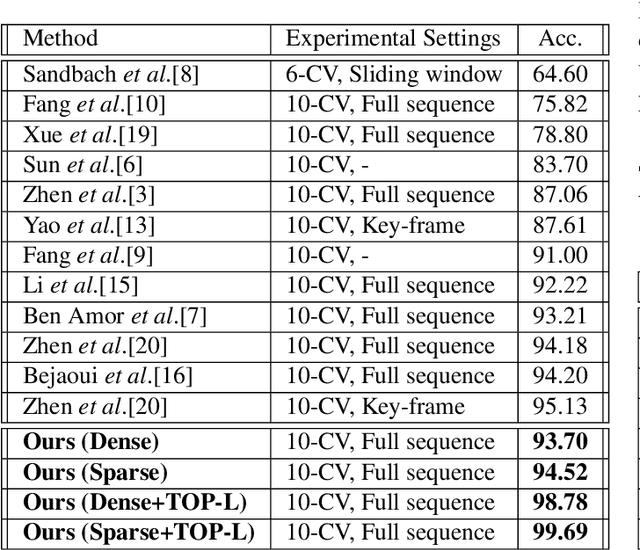
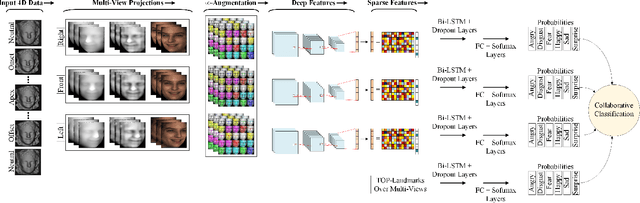
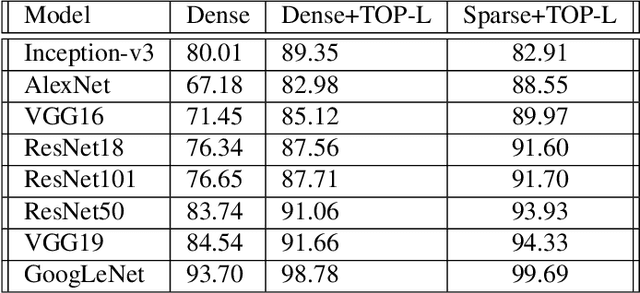
In this paper, we present a sparsity-aware deep network for automatic 4D facial expression recognition (FER). Given 4D data, we first propose a novel augmentation method to combat the data limitation problem for deep learning. This is achieved by projecting the input data into RGB and depth map images and then iteratively performing channel concatenation. Encoded in the given 3D landmarks, we also introduce TOP-landmarks over multi-views, an effective way to capture the facial muscle movements from three orthogonal planes. Importantly, we then present a sparsity-aware network to compute the sparse representations of convolutional features over multi-views for a significant and computationally convenient deep learning. For training, the TOP-landmarks and sparse representations are used to train a long short-term memory (LSTM) network. The refined predictions are achieved when the learned features collaborate over multi-views. Extensive experimental results achieved on the BU-4DFE dataset show the significance of our method over the state-of-the-art methods by reaching a promising accuracy of 99.69% for 4D FER.