Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-Aware Dialog
Paper and Code

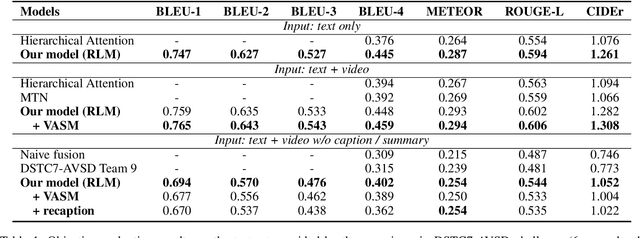
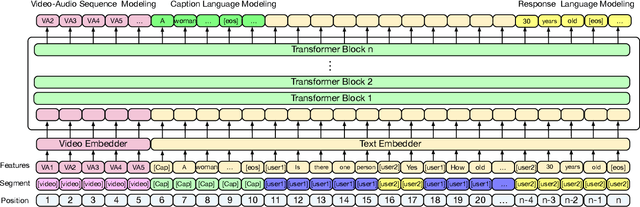
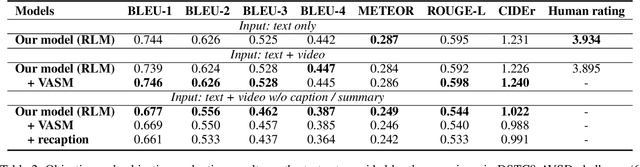
Audio-Visual Scene-Aware Dialog (AVSD) is a task to generate responses when chatting about a given video, which is organized as a track of the 8th Dialog System Technology Challenge (DSTC8). To solve the task, we propose a universal multimodal transformer and introduce the multi-task learning method to learn joint representations among different modalities as well as generate informative and fluent responses. Our method extends the natural language generation pre-trained model to multimodal dialogue generation task. Our system achieves the best performance in both objective and subjective evaluations in the challenge.
* Accepted by AAAI2020 DSTC8 workshop. Ranked 1st in DSTC8-AVSD track
View paper on