 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact-aware Sentence Split and Rephrase with Permutation Invariant Training
Paper and Code


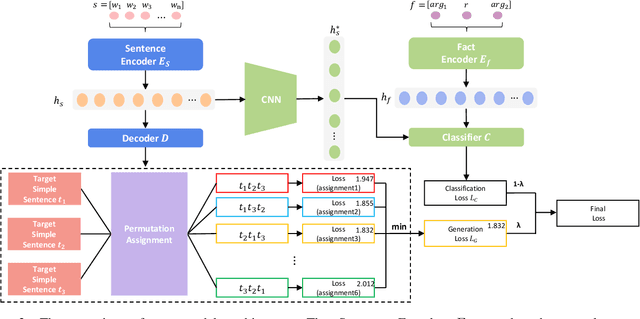
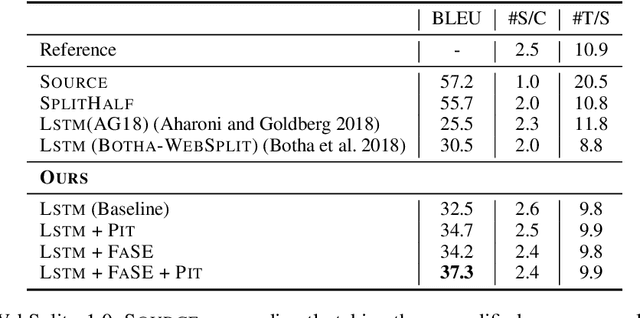
Sentence Split and Rephrase aims to break down a complex sentence into several simple sentences with its meaning preserved. Previous studies tend to address the issue by seq2seq learning from parallel sentence pairs, which takes a complex sentence as input and sequentially generates a series of simple sentences. However, the conventional seq2seq learning has two limitations for this task: (1) it does not take into account the facts stated in the long sentence; As a result, the generated simple sentences may miss or inaccurately state the facts in the original sentence. (2) The order variance of the simple sentences to be generated may confuse the seq2seq model during training because the simple sentences derived from the long source sentence could be in any order. To overcome the challenges, we first propose the Fact-aware Sentence Encoding, which enables the model to learn facts from the long sentence and thus improves the precision of sentence split; then we introduce Permutation Invariant Training to alleviate the effects of order variance in seq2seq learning for this task. Experiments on the WebSplit-v1.0 benchmark dataset show that our approaches can largely improve the performance over the previous seq2seq learning approaches. Moreover, an extrinsic evaluation on oie-benchmark verifies the effectiveness of our approaches by an observation that splitting long sentences with our state-of-the-art model as preprocessing is helpful for improving OpenIE performance.