 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Neural Architecture Search via Non-stationary Policy Gradient
Paper and Code
Jan 31, 2020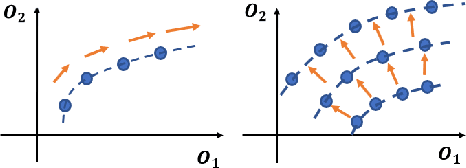
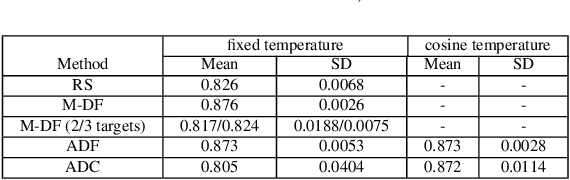
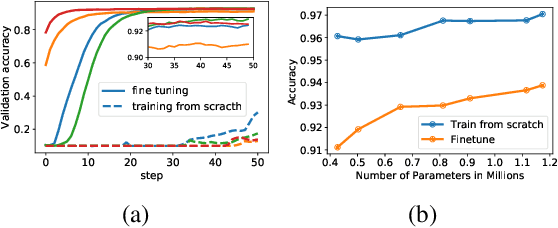
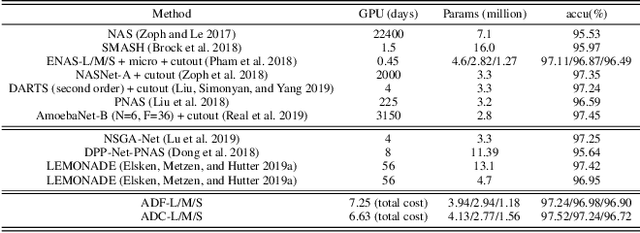
Multi-objective Neural Architecture Search (NAS) aims to discover novel architectures in the presence of multiple conflicting objectives. Despite recent progress, the problem of approximating the full Pareto front accurately and efficiently remains challenging. In this work, we explore the novel reinforcement learning (RL) based paradigm of non-stationary policy gradient (NPG). NPG utilizes a non-stationary reward function, and encourages a continuous adaptation of the policy to capture the entire Pareto front efficiently. We introduce two novel reward functions with elements from the dominant paradigms of scalarization and evolution. To handle non-stationarity, we propose a new exploration scheme using cosine temperature decay with warm restarts. For fast and accurate architecture evaluation, we introduce a novel pre-trained shared model that we continuously fine-tune throughout training. Our extensive experimental study with various datasets shows that our framework can approximate the full Pareto front well at fast speeds. Moreover, our discovered cells can achieve supreme predictive performance compared to other multi-objective NAS methods, and other single-objective NAS methods at similar network sizes. Our work demonstrates the potential of NPG as a simple, efficient, and effective paradigm for multi-objective NAS.