 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFL-IQA: Weak Supervision for Deep IQA Feature Learning
Paper and Code
Jan 20, 2020
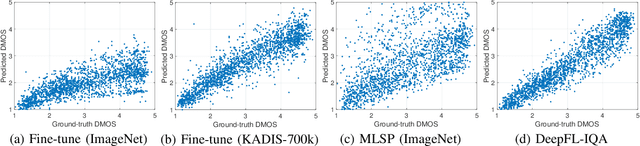

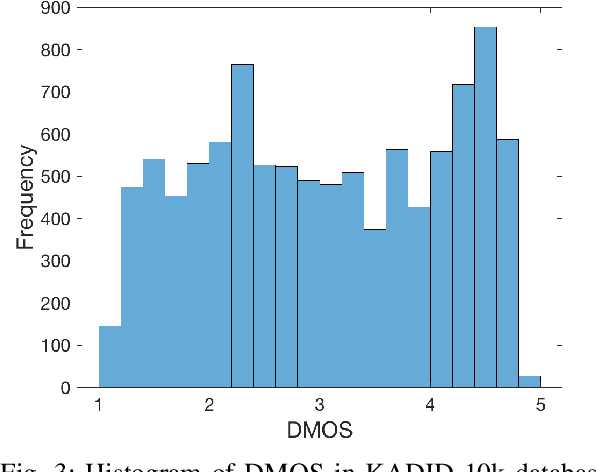
Multi-level deep-features have been driving state-of-the-art methods for aesthetics and image quality assessment (IQA). However, most IQA benchmarks are comprised of artificially distorted images, for which features derived from ImageNet under-perform. We propose a new IQA dataset and a weakly supervised feature learning approach to train features more suitable for IQA of artificially distorted images. The dataset, KADIS-700k, is far more extensive than similar works, consisting of 140,000 pristine images, 25 distortions types, totaling 700k distorted versions. Our weakly supervised feature learning is designed as a multi-task learning type training, using eleven existing full-reference IQA metrics as proxies for differential mean opinion scores. We also introduce a benchmark database, KADID-10k, of artificially degraded images, each subjectively annotated by 30 crowd workers. We make use of our derived image feature vectors for (no-reference) image quality assessment by training and testing a shallow regression network on this database and five other benchmark IQA databases. Our method, termed DeepFL-IQA, performs better than other feature-based no-reference IQA methods and also better than all tested full-reference IQA methods on KADID-10k. For the other five benchmark IQA databases, DeepFL-IQA matches the performance of the best existing end-to-end deep learning-based methods on average.