 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence Time Optimization for Federated Learning over Wireless Networks
Paper and Code
Jan 22, 2020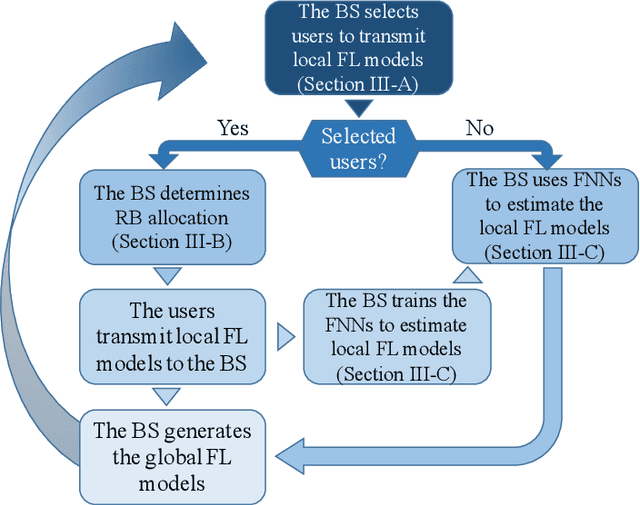
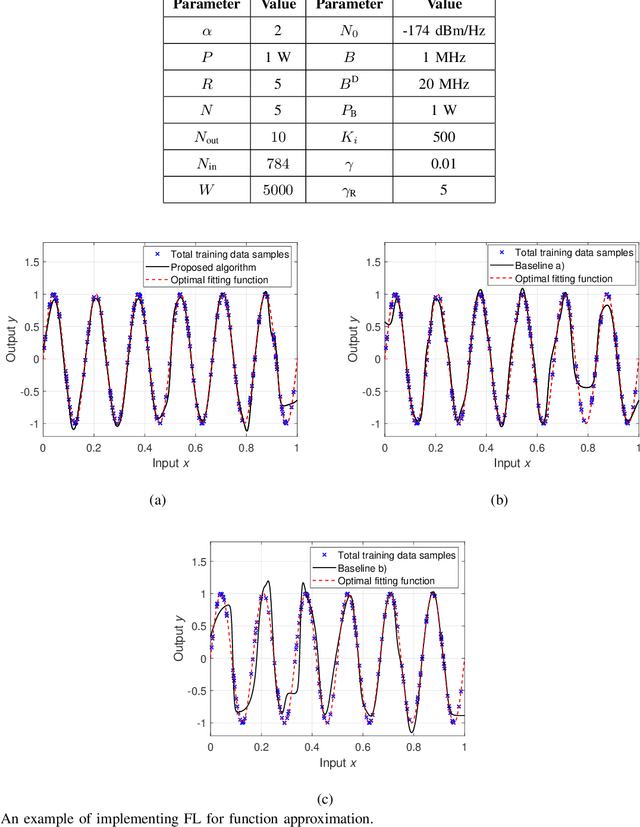

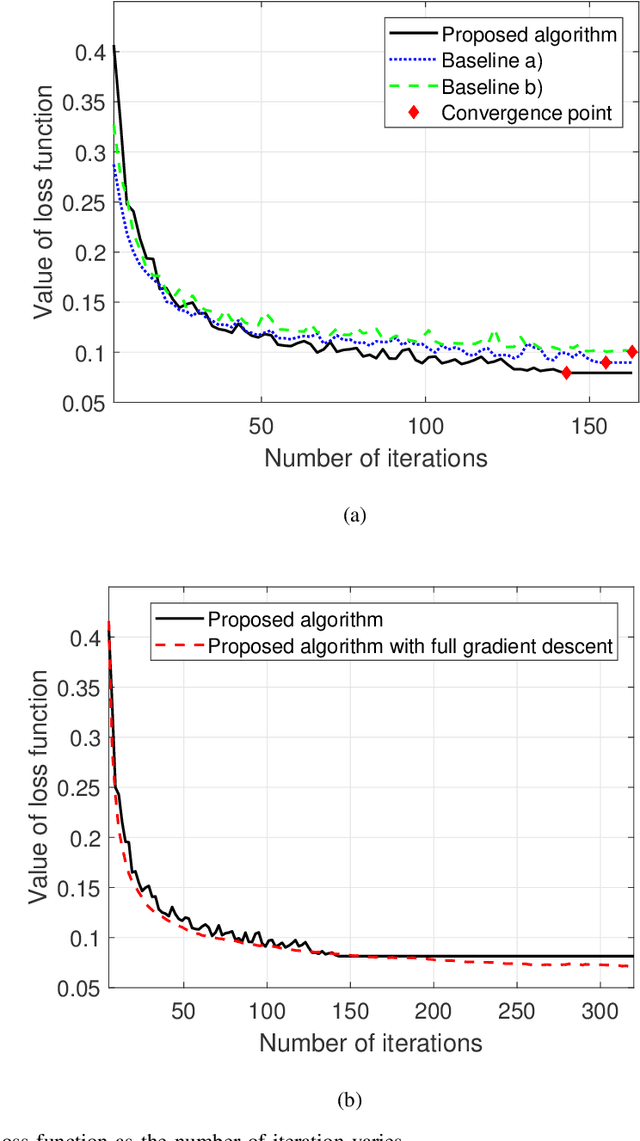
In this paper, the convergence time of federated learning (FL), when deployed over a realistic wireless network, is studied. In particular, a wireless network is considered in which wireless users transmit their local FL models (trained using their locally collected data) to a base station (BS). The BS, acting as a central controller, generates a global FL model using the received local FL models and broadcasts it back to all users. Due to the limited number of resource blocks (RBs) in a wireless network, only a subset of users can be selected to transmit their local FL model parameters to the BS at each learning step. Moreover, since each user has unique training data samples, the BS prefers to include all local user FL models to generate a converged global FL model. Hence, the FL performance and convergence time will be significantly affected by the user selection scheme. Therefore, it is necessary to design an appropriate user selection scheme that enables users of higher importance to be selected more frequently. This joint learning, wireless resource allocation, and user selection problem is formulated as an optimization problem whose goal is to minimize the FL convergence time while optimizing the FL performance. To solve this problem, a probabilistic user selection scheme is proposed such that the BS is connected to the users whose local FL models have significant effects on its global FL model with high probabilities. Given the user selection policy, the uplink RB allocation can be determined. To further reduce the FL convergence time, artificial neural networks (ANNs) are used to estimate the local FL models of the users that are not allocated any RBs for local FL model transmission at each given learning step, which enables the BS to enhance its global FL model and improve the FL convergence speed and performance.