 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEV Dataset: Predicting Expressions Evoked by Diverse Videos
Paper and Code

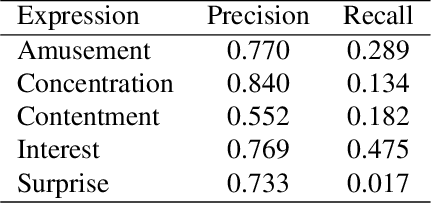
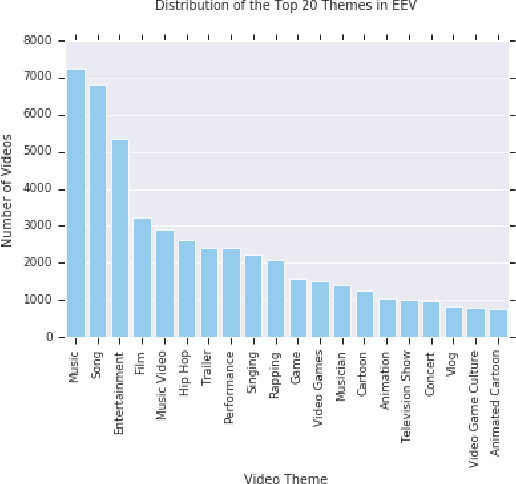
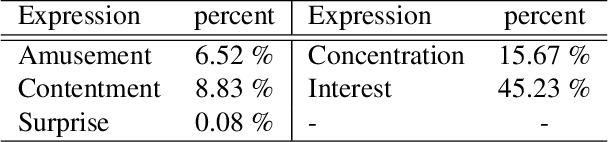
When we watch videos, the visual and auditory information we experience can evoke a range of affective responses. The ability to automatically predict evoked affect from videos can help recommendation systems and social machines better interact with their users. Here, we introduce the Evoked Expressions in Videos (EEV) dataset, a large-scale dataset for studying viewer responses to videos based on their facial expressions. The dataset consists of a total of 4.8 million annotations of viewer facial reactions to 18,541 videos. We use a publicly available video corpus to obtain a diverse set of video content. The training split is fully machine-annotated, while the validation and test splits have both human and machine annotations. We verify the performance of our machine annotations with human raters to have an average precision of 73.3%. We establish baseline performance on the EEV dataset using an existing multimodal recurrent model. Our results show that affective information can be learned from EEV, but with a MAP of 20.32%, there is potential for improvement. This gap motivates the need for new approaches for understanding affective content. Our transfer learning experiments show an improvement in performance on the LIRIS-ACCEDE video dataset when pre-trained on EEV. We hope that the size and diversity of the EEV dataset will encourage further explorations in video understanding and affective computing.