 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Coding for Human and Machine Vision: A Scalable Image Coding Approach
Paper and Code
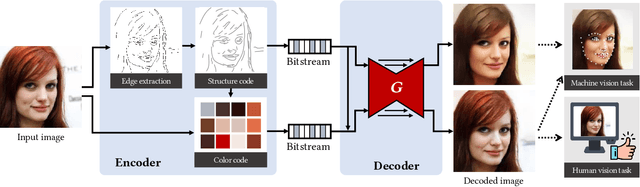

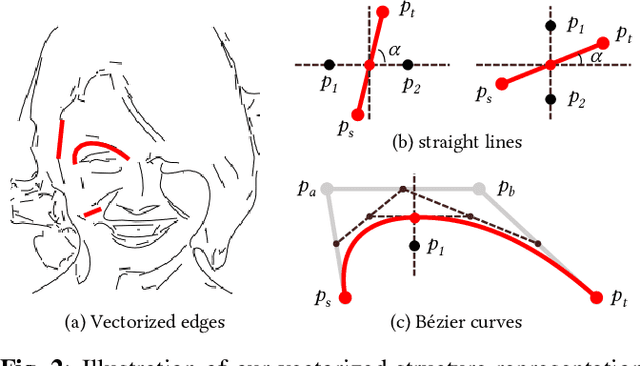

The past decades have witnessed the rapid development of image and video coding techniques in the era of big data. However, the signal fidelity-driven coding pipeline design limits the capability of the existing image/video coding frameworks to fulfill the needs of both machine and human vision. In this paper, we come up with a novel image coding framework by leveraging both the compressive and the generative models, to support machine vision and human perception tasks jointly. Given an input image, the feature analysis is first applied, and then the generative model is employed to perform image reconstruction with features and additional reference pixels, in which compact edge maps are extracted in this work to connect both kinds of vision in a scalable way. The compact edge map serves as the basic layer for machine vision tasks, and the reference pixels act as a sort of enhanced layer to guarantee signal fidelity for human vision. By introducing advanced generative models, we train a flexible network to reconstruct images from compact feature representations and the reference pixels. Experimental results demonstrate the superiority of our framework in both human visual quality and facial landmark detection, which provide useful evidence on the emerging standardization efforts on MPEG VCM (Video Coding for Machine).