 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Hyperparameter Tuning and Feature Selection using Filter Ensembles
Paper and Code

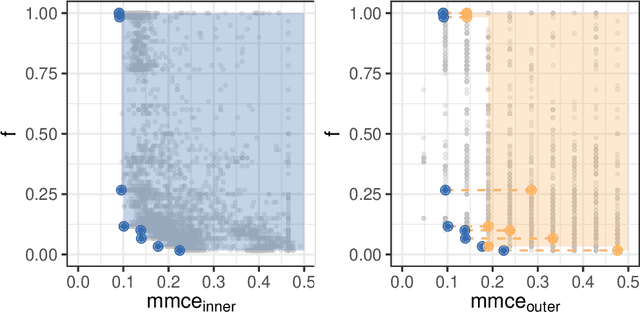
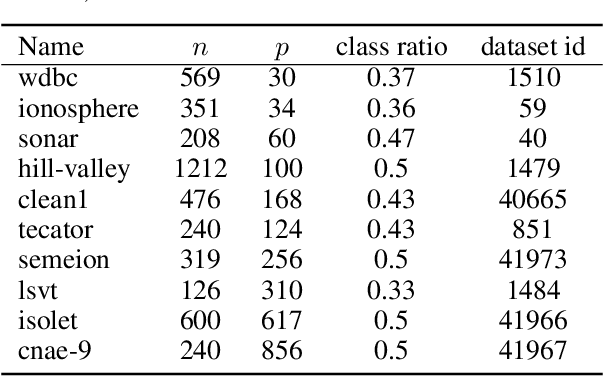
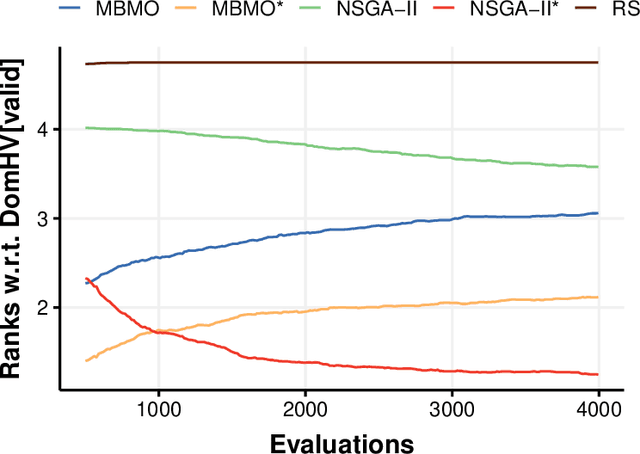
Both feature selection and hyperparameter tuning are key tasks in machine learning. Hyperparameter tuning is often useful to increase model performance, while feature selection is undertaken to attain sparse models. Sparsity may yield better model interpretability and lower cost of data acquisition, data handling and model inference. While sparsity may have a beneficial or detrimental effect on predictive performance, a small drop in performance may be acceptable in return for a substantial gain in sparseness. We therefore treat feature selection as a multi-objective optimization task. We perform hyperparameter tuning and feature selection simultaneously because the choice of features of a model may influence what hyperparameters perform well. We present, benchmark, and compare two different approaches for multi-objective joint hyperparameter optimization and feature selection: The first uses multi-objective model-based optimization. The second is an evolutionary NSGA-II-based wrapper approach to feature selection which incorporates specialized sampling, mutation and recombination operators. Both methods make use of parameterized filter ensembles. While model-based optimization needs fewer objective evaluations to achieve good performance, it incurs computational overhead compared to the NSGA-II, so the preferred choice depends on the cost of evaluating a model on given data.