 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorize, Then Recall: A Generative Framework for Low Bit-rate Surveillance Video Compression
Paper and Code
Dec 30, 2019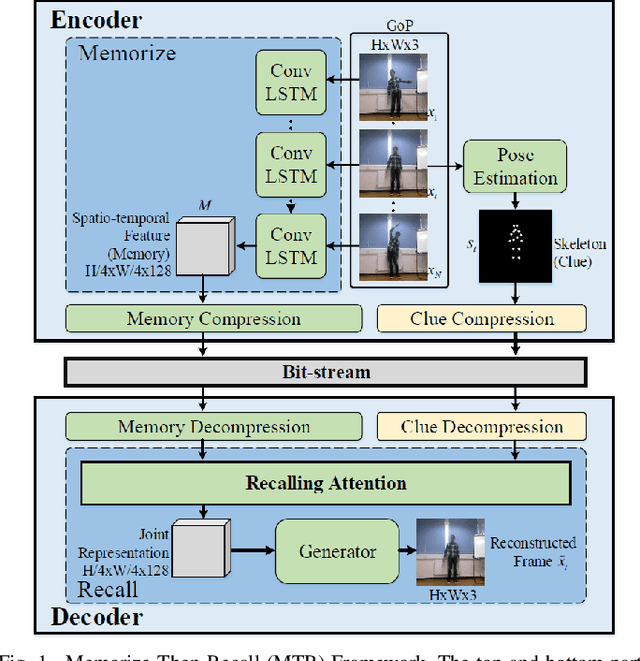
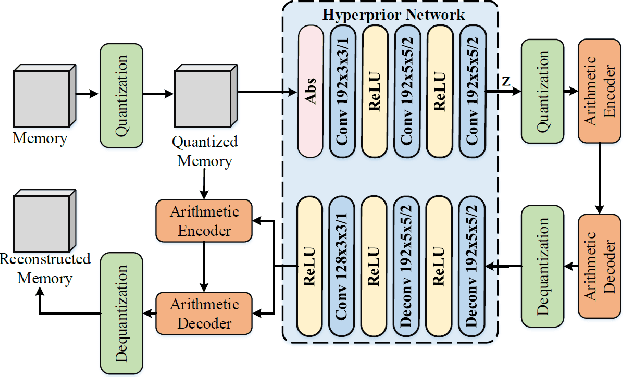
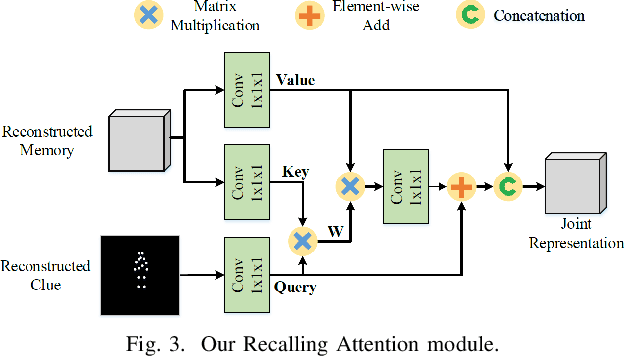

Surveillance video applications grow dramatically in public safety and daily life, which often detect and recognize moving objects inside video signals. Existing surveillance video compression schemes are still based on traditional hybrid coding frameworks handling temporal redundancy by block-wise motion compensation mechanism, lacking the extraction and utilization of inherent structure information. In this paper, we alleviate this issue by decomposing surveillance video signals into the structure of a global spatio-temporal feature (memory) and skeleton for each frame (clue). The memory is abstracted by a recurrent neural network across Group of Pictures (GoP) inside one video sequence, representing appearance for elements that appeared inside GoP. While the skeleton is obtained by the specific pose estimator, it served as a clue for recalling memory. In addition, we introduce an attention mechanism to learn the relationships between appearance and skeletons. And we reconstruct each frame with an adversarial training process. Experimental results demonstrate that our approach can effectively generate realistic frames from appearance and skeleton accordingly. Compared with the latest video compression standard H.265, it shows much higher compression performance on surveillance video.