 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of the Learnability of Relational Properties
Paper and Code
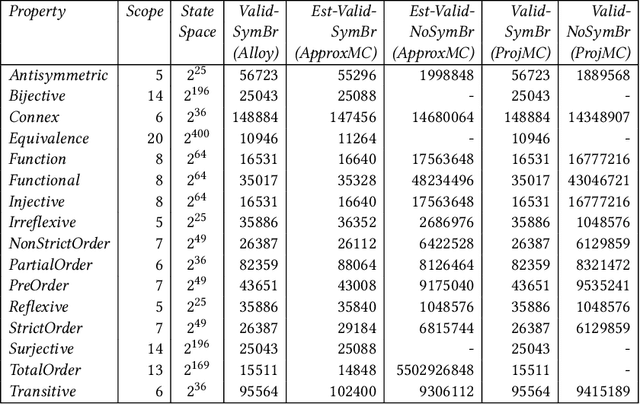
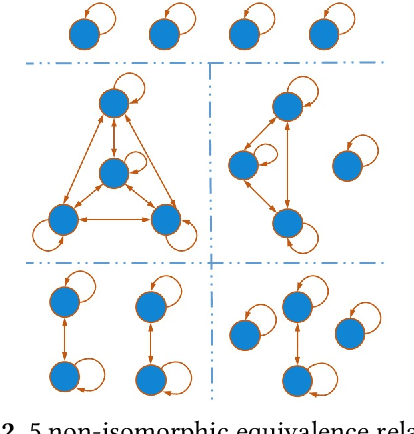
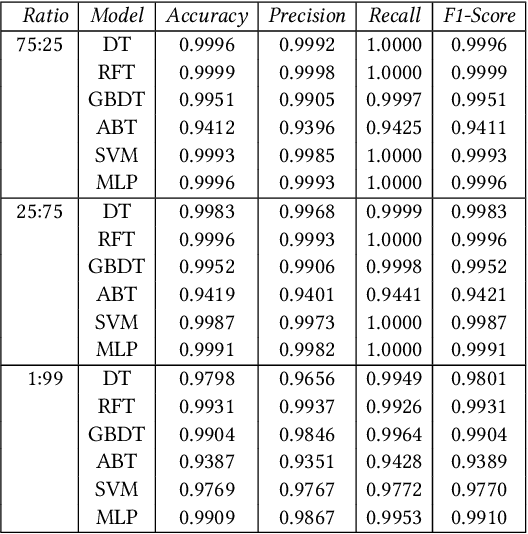
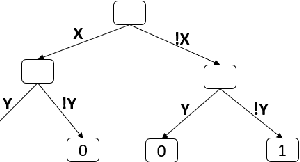
Relational properties, e.g., the connectivity structure of nodes in a distributed system, have many applications in software design and analysis. However, such properties often have to be written manually, which can be costly and error-prone. This paper introduces the MCML approach for empirically studying the learnability of a key class of such properties that can be expressed in the well-known software design language Alloy. A key novelty of MCML is quantification of the performance of and semantic differences among trained machine learning (ML) models, specifically decision trees, with respect to entire input spaces (up to a bound on the input size), and not just for given training and test datasets (as is the common practice). MCML reduces the quantification problems to the classic complexity theory problem of model counting, and employs state-of-the-art approximate and exact model counters for high efficiency. The results show that relatively simple ML models can achieve surprisingly high performance (accuracy and F1 score) at learning relational properties when evaluated in the common setting of using training and test datasets -- even when the training dataset is much smaller than the test dataset -- indicating the seeming simplicity of learning these properties. However, the use of MCML metrics based on model counting shows that the performance can degrade substantially when tested against the whole (bounded) input space, indicating the high complexity of precisely learning these properties, and the usefulness of model counting in quantifying the true accuracy.