 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Automating Review Recommendation for Code Changes
Paper and Code
Dec 20, 2019
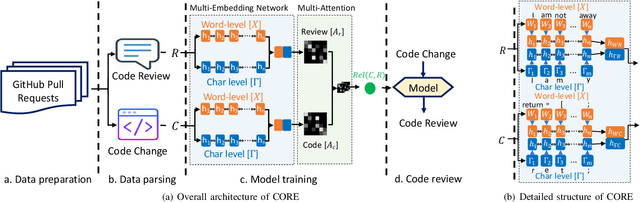
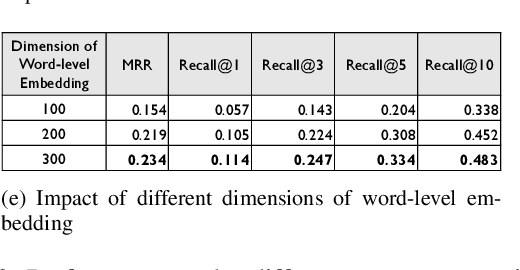
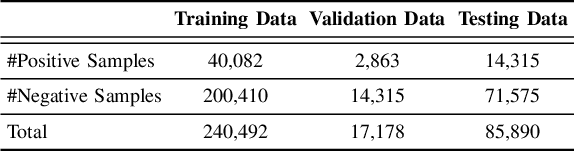
Code review is a common process that is used by developers, in which a reviewer provides useful comments or points out defects in the submitted source code changes via pull request. Code review has been widely used for both industry and open-source projects due to its capacity in early defect identification, project maintenance, and code improvement. With rapid updates on project developments, code review becomes a non-trivial and labor-intensive task for reviewers. Thus, an automated code review engine can be beneficial and useful for project development in practice. Although there exist prior studies on automating the code review process by adopting static analysis tools or deep learning techniques, they often require external sources such as partial or full source code for accurate review suggestion. In this paper, we aim at automating the code review process only based on code changes and the corresponding reviews but with better performance. The hinge of accurate code review suggestion is to learn good representations for both code changes and reviews. To achieve this with limited source, we design a multi-level embedding (i.e., word embedding and character embedding) approach to represent the semantics provided by code changes and reviews. The embeddings are then well trained through a proposed attentional deep learning model, as a whole named CORE. We evaluate the effectiveness of CORE on code changes and reviews collected from 19 popular Java projects hosted on Github. Experimental results show that our model CORE can achieve significantly better performance than the state-of-the-art model (DeepMem), with an increase of 131.03% in terms of Recall@10 and 150.69% in terms of Mean Reciprocal Rank. Qualitative general word analysis among project developers also demonstrates the performance of CORE in automating code review.