Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTje: A Dutch BERT Model
Paper and Code
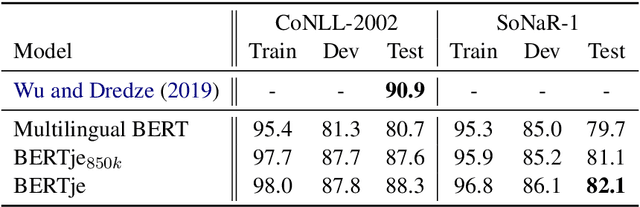
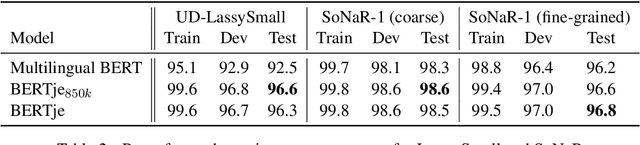


The transformer-based pre-trained language model BERT has helped to improve state-of-the-art performance on many natural language processing (NLP) tasks. Using the same architecture and parameters, we developed and evaluated a monolingual Dutch BERT model called BERTje. Compared to the multilingual BERT model, which includes Dutch but is only based on Wikipedia text, BERTje is based on a large and diverse dataset of 2.4 billion tokens. BERTje consistently outperforms the equally-sized multilingual BERT model on downstream NLP tasks (part-of-speech tagging, named-entity recognition, semantic role labeling, and sentiment analysis). Our pre-trained Dutch BERT model is made available at https://github.com/wietsedv/bertje.
View paper on