 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks Weights Quantization: Target None-retraining Ternary (TNT)
Paper and Code
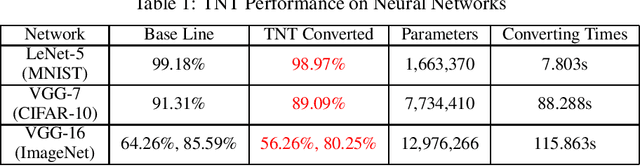
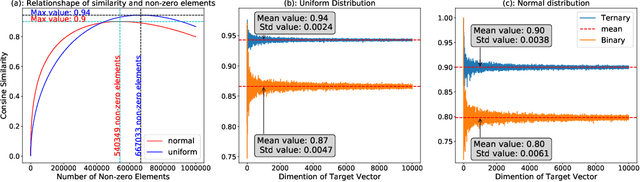
Quantization of weights of deep neural networks (DNN) has proven to be an effective solution for the purpose of implementing DNNs on edge devices such as mobiles, ASICs and FPGAs, because they have no sufficient resources to support computation involving millions of high precision weights and multiply-accumulate operations. This paper proposes a novel method to compress vectors of high precision weights of DNNs to ternary vectors, namely a cosine similarity based target non-retraining ternary (TNT) compression method. Our method leverages cosine similarity instead of Euclidean distances as commonly used in the literature and succeeds in reducing the size of the search space to find optimal ternary vectors from 3N to N, where N is the dimension of target vectors. As a result, the computational complexity for TNT to find theoretically optimal ternary vectors is only O(N log(N)). Moreover, our experiments show that, when we ternarize models of DNN with high precision parameters, the obtained quantized models can exhibit sufficiently high accuracy so that re-training models is not necessary.