 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
Paper and Code
Dec 17, 2019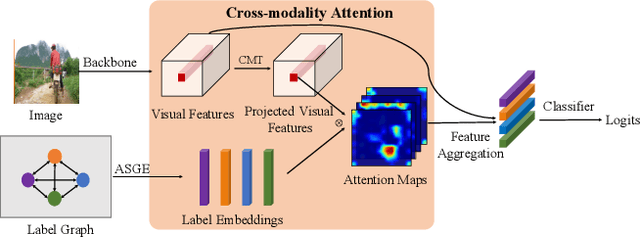
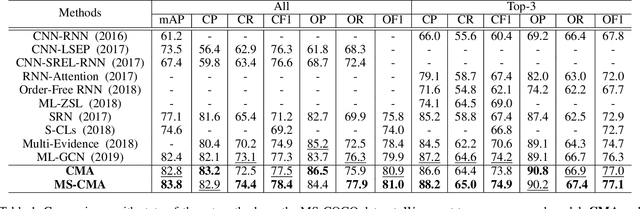
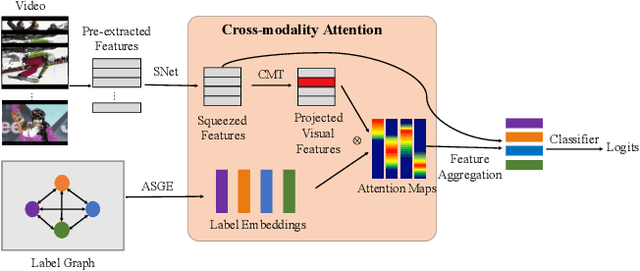
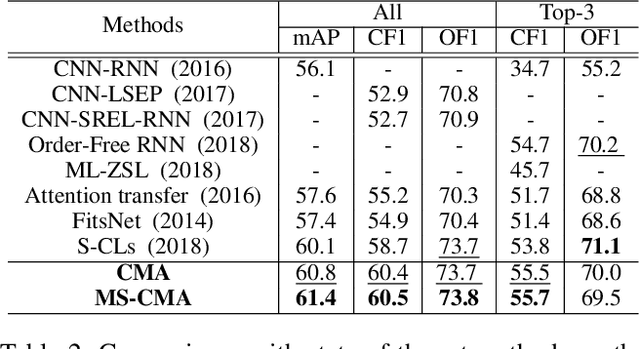
Multi-label image and video classification are fundamental yet challenging tasks in computer vision. The main challenges lie in capturing spatial or temporal dependencies between labels and discovering the locations of discriminative features for each class. In order to overcome these challenges, we propose to use cross-modality attention with semantic graph embedding for multi label classification. Based on the constructed label graph, we propose an adjacency-based similarity graph embedding method to learn semantic label embeddings, which explicitly exploit label relationships. Then our novel cross-modality attention maps are generated with the guidance of learned label embeddings. Experiments on two multi-label image classification datasets (MS-COCO and NUS-WIDE) show our method outperforms other existing state-of-the-arts. In addition, we validate our method on a large multi-label video classification dataset (YouTube-8M Segments) and the evaluation results demonstrate the generalization capability of our method.