 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealization of spatial sparseness by deep ReLU nets with massive data
Paper and Code
Dec 16, 2019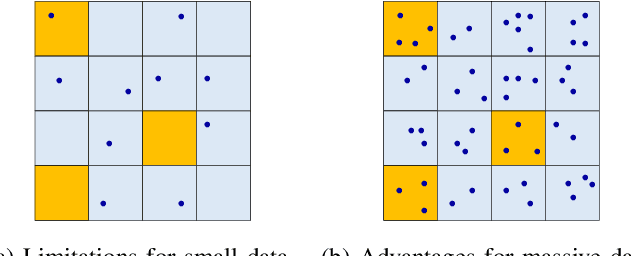
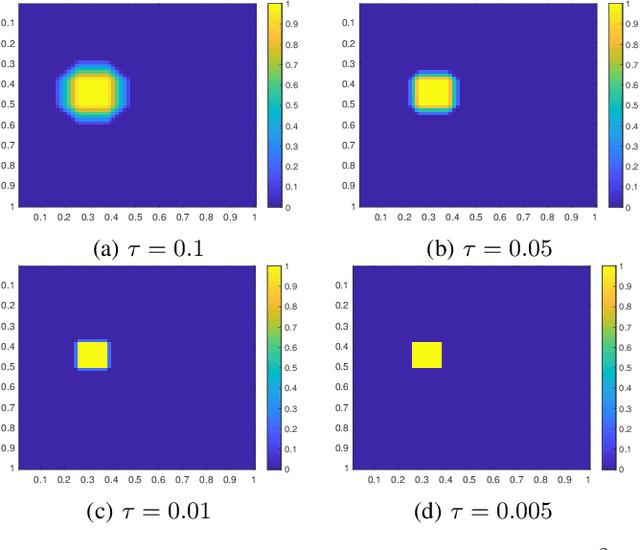
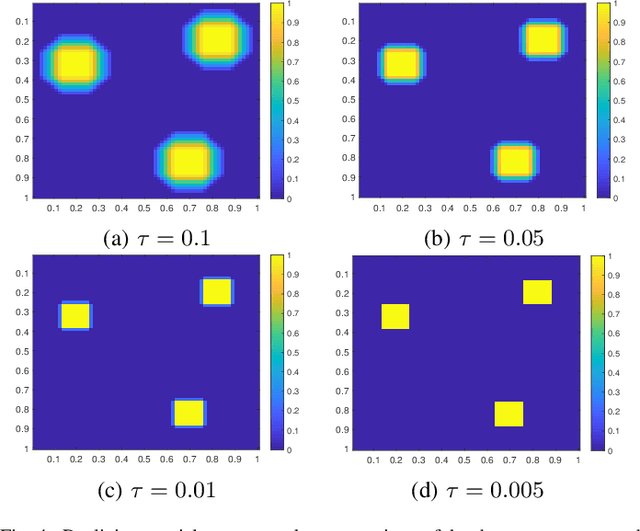
The great success of deep learning poses urgent challenges for understanding its working mechanism and rationality. The depth, structure, and massive size of the data are recognized to be three key ingredients for deep learning. Most of the recent theoretical studies for deep learning focus on the necessity and advantages of depth and structures of neural networks. In this paper, we aim at rigorous verification of the importance of massive data in embodying the out-performance of deep learning. To approximate and learn spatially sparse and smooth functions, we establish a novel sampling theorem in learning theory to show the necessity of massive data. We then prove that implementing the classical empirical risk minimization on some deep nets facilitates in realization of the optimal learning rates derived in the sampling theorem. This perhaps explains why deep learning performs so well in the era of big data.