 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2016 Task 4: Sentiment Analysis in Twitter
Paper and Code
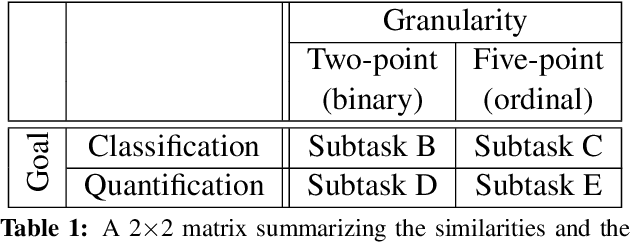
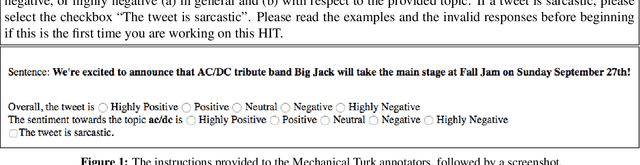
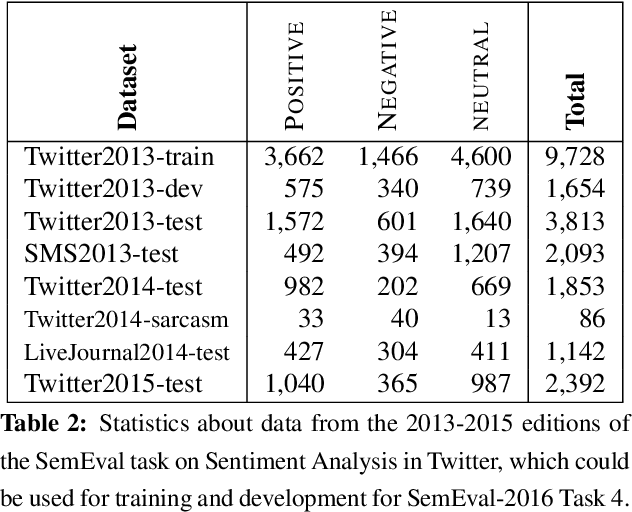
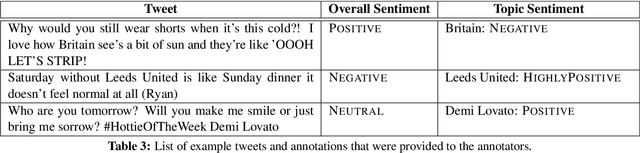
This paper discusses the fourth year of the ``Sentiment Analysis in Twitter Task''. SemEval-2016 Task 4 comprises five subtasks, three of which represent a significant departure from previous editions. The first two subtasks are reruns from prior years and ask to predict the overall sentiment, and the sentiment towards a topic in a tweet. The three new subtasks focus on two variants of the basic ``sentiment classification in Twitter'' task. The first variant adopts a five-point scale, which confers an ordinal character to the classification task. The second variant focuses on the correct estimation of the prevalence of each class of interest, a task which has been called quantification in the supervised learning literature. The task continues to be very popular, attracting a total of 43 teams.