 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadratic Q-network for Learning Continuous Control for Autonomous Vehicles
Paper and Code
Nov 29, 2019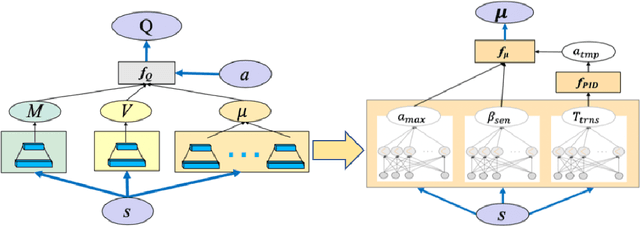

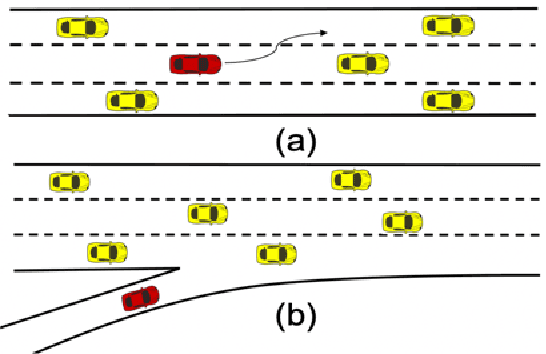

Reinforcement Learning algorithms have recently been proposed to learn time-sequential control policies in the field of autonomous driving. Direct applications of Reinforcement Learning algorithms with discrete action space will yield unsatisfactory results at the operational level of driving where continuous control actions are actually required. In addition, the design of neural networks often fails to incorporate the domain knowledge of the targeting problem such as the classical control theories in our case. In this paper, we propose a hybrid model by combining Q-learning and classic PID (Proportion Integration Differentiation) controller for handling continuous vehicle control problems under dynamic driving environment. Particularly, instead of using a big neural network as Q-function approximation, we design a Quadratic Q-function over actions with multiple simple neural networks for finding optimal values within a continuous space. We also build an action network based on the domain knowledge of the control mechanism of a PID controller to guide the agent to explore optimal actions more efficiently.We test our proposed approach in simulation under two common but challenging driving situations, the lane change scenario and ramp merge scenario. Results show that the autonomous vehicle agent can successfully learn a smooth and efficient driving behavior in both situations.