 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition via Pose-Based Graph Convolutional Networks with Intermediate Dense Supervision
Paper and Code
Nov 28, 2019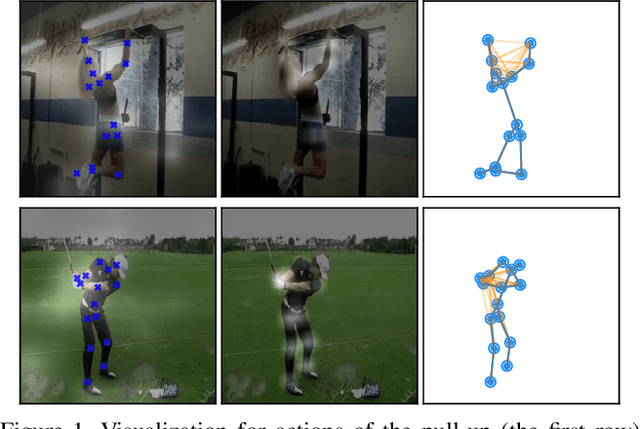
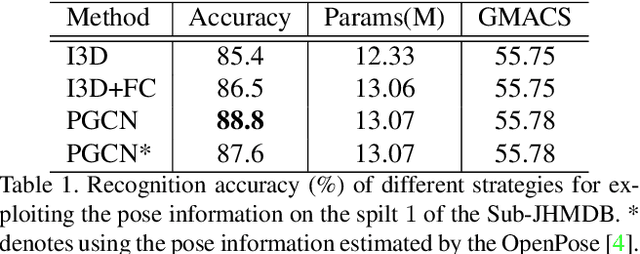
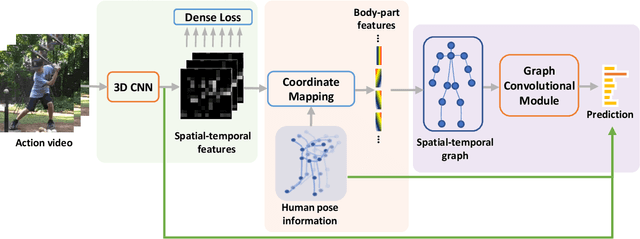
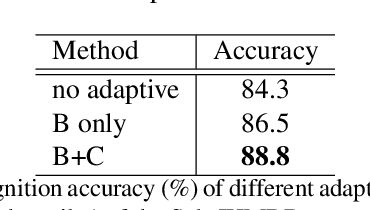
Pose-based action recognition has drawn considerable attention recently. Existing methods exploit the joint positions to extract the body-part features from the activation map of the convolutional networks to assist human action recognition. However, these features are simply concatenated or max-pooled in previous works. The structured correlations among the body parts, which are essential for understanding complex human actions, are not fully exploited. To address the problem, we propose a pose-based graph convolutional network (PGCN), which encodes the body-part features into a human-based spatiotemporal graph, and explicitly models their correlations with a novel light-weight adaptive graph convolutional module to produce a highly discriminative representation for human action recognition. Besides, we discover that the backbone network tends to identify patterns from the most discriminative areas of the input regardless of the others. Thus the features pooled by the joint positions from other areas are less informative, which consequently hampers the performance of the followed aggregation process for recognizing actions. To alleviate this issue, we introduce a simple intermediate dense supervision mechanism for the backbone network, which adequately addresses the problem with no extra computation cost during inference. We evaluate the proposed approach on three popular benchmarks for pose-based action recognition tasks, i.e., Sub-JHMDB, PennAction and NTU-RGBD, where our approach significantly outperforms state-of-the-arts without the bells and whistles.