 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Hierarchical Bayesian Tucker Decomposition
Paper and Code

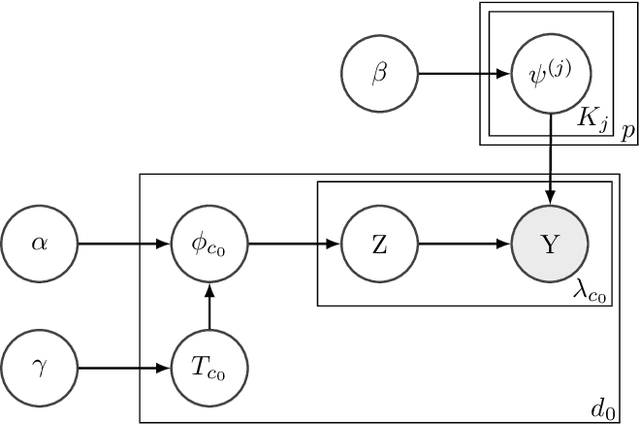
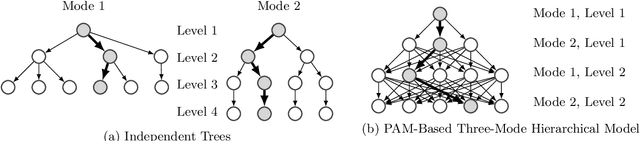

Our research focuses on studying and developing methods for reducing the dimensionality of large datasets, common in biomedical applications. A major problem when learning information about patients based on genetic sequencing data is that there are often more feature variables (genetic data) than observations (patients). This makes direct supervised learning difficult. One way of reducing the feature space is to use latent Dirichlet allocation in order to group genetic variants in an unsupervised manner. Latent Dirichlet allocation is a common model in natural language processing, which describes a document as a mixture of topics, each with a probability of generating certain words. This can be generalized as a Bayesian tensor decomposition to account for multiple feature variables. While we made some progress improving and modifying these methods, our significant contributions are with hierarchical topic modeling. We developed distinct methods of incorporating hierarchical topic modeling, based on nested Chinese restaurant processes and Pachinko Allocation Machine, into Bayesian tensor decompositions. We apply these models to predict whether or not patients have autism spectrum disorder based on genetic sequencing data. We examine a dataset from National Database for Autism Research consisting of paired siblings -- one with autism, and the other without -- and counts of their genetic variants. Additionally, we linked the genes with their Reactome biological pathways. We combine this information into a tensor of patients, counts of their genetic variants, and the membership of these genes in pathways. Once we decompose this tensor, we use logistic regression on the reduced features in order to predict if patients have autism. We also perform a similar analysis of a dataset of patients with one of four common types of cancer (breast, lung, prostate, and colorectal).