 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Enhanced Convolutional Network for Facial Video Hallucination
Paper and Code
Nov 23, 2019
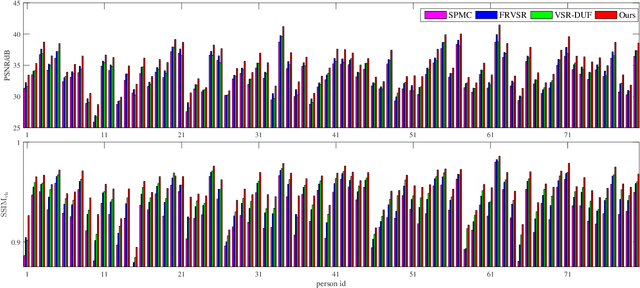
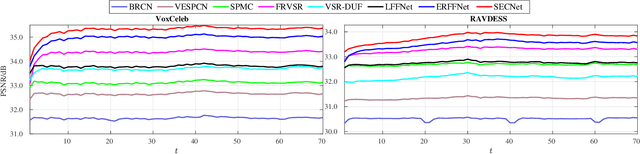
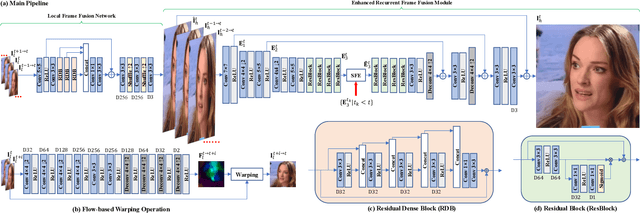
As a domain-specific super-resolution problem, facial image hallucination has enjoyed a series of breakthroughs thanks to the advances of deep convolutional neural networks. However, the direct migration of existing methods to video is still difficult to achieve good performance due to its lack of alignment and consistency modelling in temporal domain. Taking advantage of high inter-frame dependency in videos, we propose a self-enhanced convolutional network for facial video hallucination. It is implemented by making full usage of preceding super-resolved frames and a temporal window of adjacent low-resolution frames. Specifically, the algorithm first obtains the initial high-resolution inference of each frame by taking into consideration a sequence of consecutive low-resolution inputs through temporal consistency modelling. It further recurrently exploits the reconstructed results and intermediate features of a sequence of preceding frames to improve the initial super-resolution of the current frame by modelling the coherence of structural facial features across frames. Quantitative and qualitative evaluations demonstrate the superiority of the proposed algorithm against state-of-the-art methods. Moreover, our algorithm also achieves excellent performance in the task of general video super-resolution in a single-shot setting.