 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Operation Importance for Differentiable Neural Architecture Search
Paper and Code
Nov 24, 2019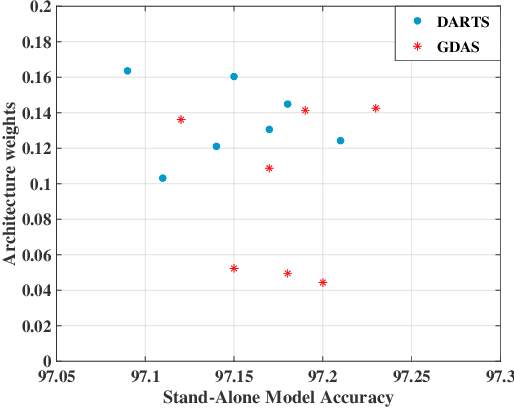
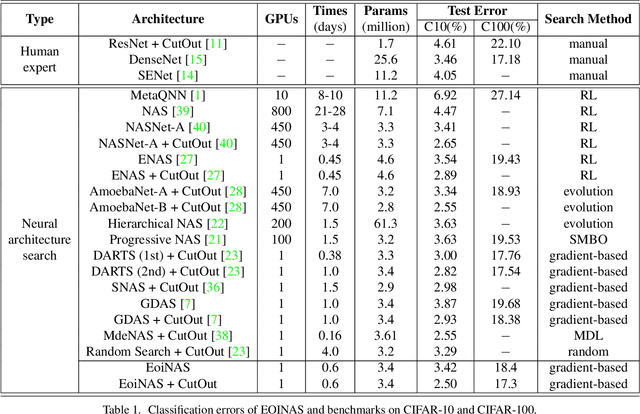
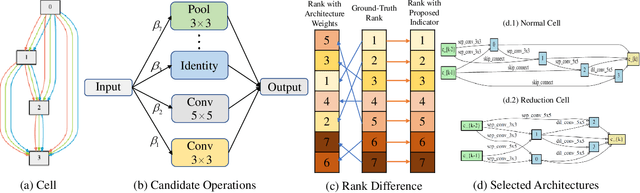
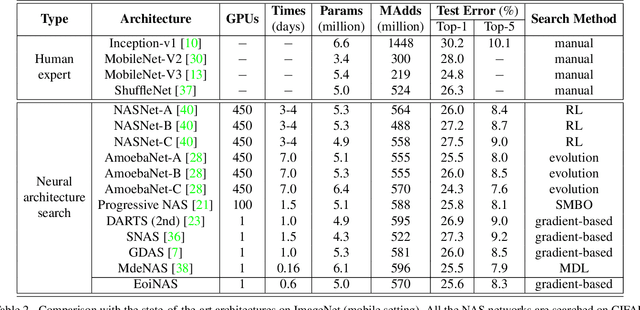
Recently, differentiable neural architecture search methods significantly reduce the search cost by constructing a super network and relax the architecture representation by assigning architecture weights to the candidate operations. All the existing methods determine the importance of each operation directly by architecture weights. However, architecture weights cannot accurately reflect the importance of each operation; that is, the operation with the highest weight might not related to the best performance. To alleviate this deficiency, we propose a simple yet effective solution to neural architecture search, termed as exploiting operation importance for effective neural architecture search (EoiNAS), in which a new indicator is proposed to fully exploit the operation importance and guide the model search. Based on this new indicator, we propose a gradual operation pruning strategy to further improve the search efficiency and accuracy. Experimental results have demonstrated the effectiveness of the proposed method. Specifically, we achieve an error rate of 2.50\% on CIFAR-10, which significantly outperforms state-of-the-art methods. When transferred to ImageNet, it achieves the top-1 error of 25.6\%, comparable to the state-of-the-art performance under the mobile setting.