 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Level Factors for Sentence Deletion in Text Simplification
Paper and Code
Nov 26, 2019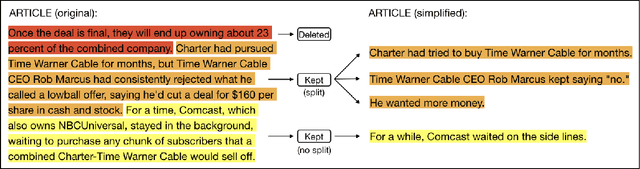
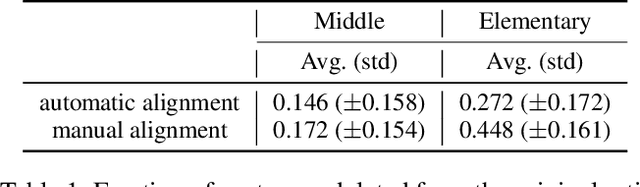
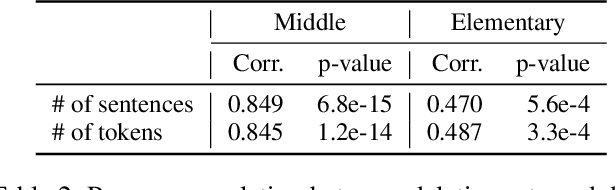
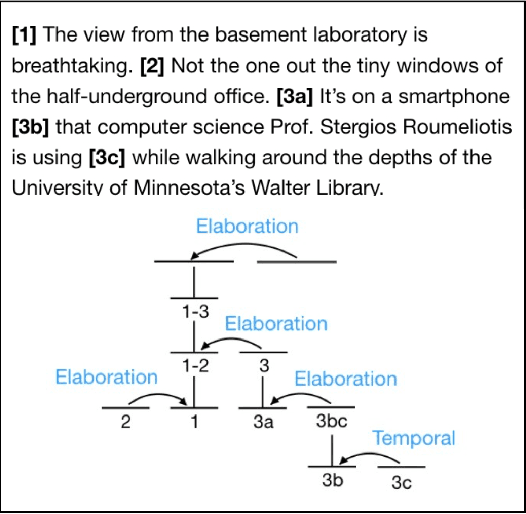
This paper presents a data-driven study focusing on analyzing and predicting sentence deletion --- a prevalent but understudied phenomenon in document simplification --- on a large English text simplification corpus. We inspect various document and discourse factors associated with sentence deletion, using a new manually annotated sentence alignment corpus we collected. We reveal that professional editors utilize different strategies to meet readability standards of elementary and middle schools. To predict whether a sentence will be deleted during simplification to a certain level, we harness automatically aligned data to train a classification model. Evaluated on our manually annotated data, our best models reached F1 scores of 65.2 and 59.7 for this task at the levels of elementary and middle school, respectively. We find that discourse level factors contribute to the challenging task of predicting sentence deletion for simplification.