 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd Density Forecasting by Modeling Patch-based Dynamics
Paper and Code
Nov 22, 2019
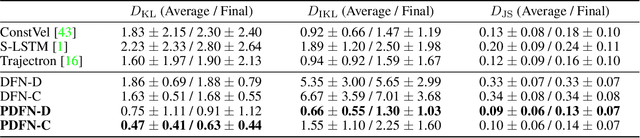
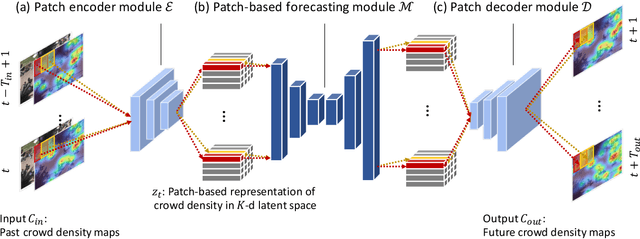
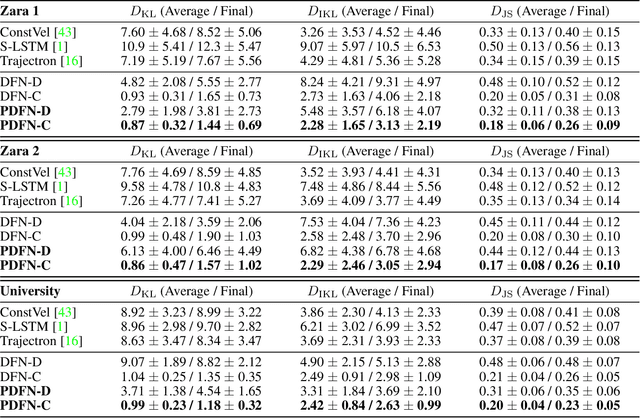
Forecasting human activities observed in videos is a long-standing challenge in computer vision, which leads to various real-world applications such as mobile robots, autonomous driving, and assistive systems. In this work, we present a new visual forecasting task called crowd density forecasting. Given a video of a crowd captured by a surveillance camera, our goal is to predict how that crowd will move in future frames. To address this task, we have developed the patch-based density forecasting network (PDFN), which enables forecasting over a sequence of crowd density maps describing how crowded each location is in each video frame. PDFN represents a crowd density map based on spatially overlapping patches and learns density dynamics patch-wise in a compact latent space. This enables us to model diverse and complex crowd density dynamics efficiently, even when the input video involves a variable number of crowds that each move independently. Experimental results with several public datasets demonstrate the effectiveness of our approach compared with state-of-the-art forecasting methods.