 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shot Network Compression via Cross Distillation
Paper and Code
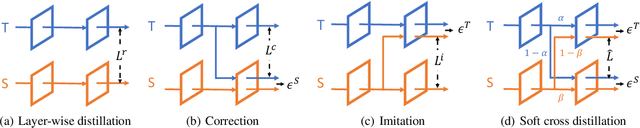
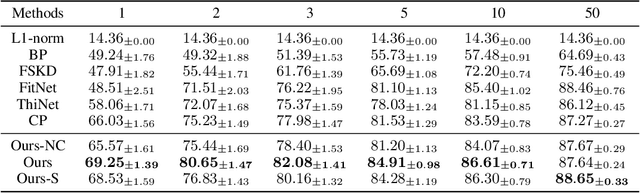
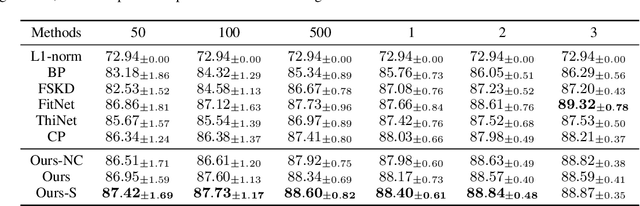
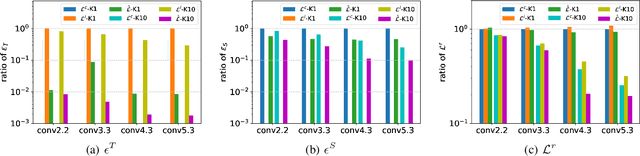
Model compression has been widely adopted to obtain light-weighted deep neural networks. Most prevalent methods, however, require fine-tuning with sufficient training data to ensure accuracy, which could be challenged by privacy and security issues. As a compromise between privacy and performance, in this paper we investigate few shot network compression: given few samples per class, how can we effectively compress the network with negligible performance drop? The core challenge of few shot network compression lies in high estimation errors from the original network during inference, since the compressed network can easily over-fits on the few training instances. The estimation errors could propagate and accumulate layer-wisely and finally deteriorate the network output. To address the problem, we propose cross distillation, a novel layer-wise knowledge distillation approach. By interweaving hidden layers of teacher and student network, layer-wisely accumulated estimation errors can be effectively reduced.The proposed method offers a general framework compatible with prevalent network compression techniques such as pruning. Extensive experiments on benchmark datasets demonstrate that cross distillation can significantly improve the student network's accuracy when only a few training instances are available.