 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Precision Scaling for Distributed Deep Learning
Paper and Code
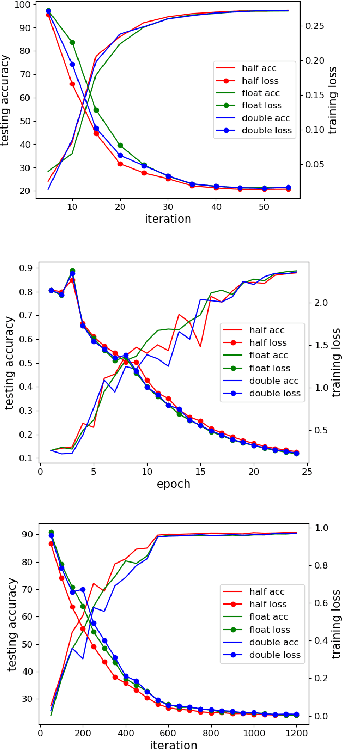
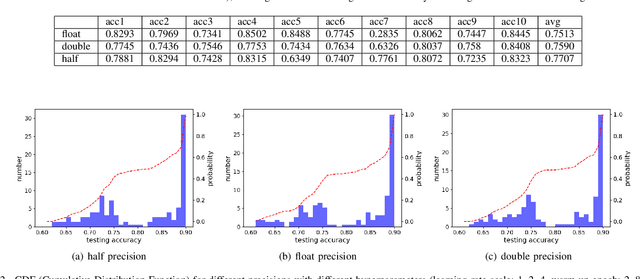
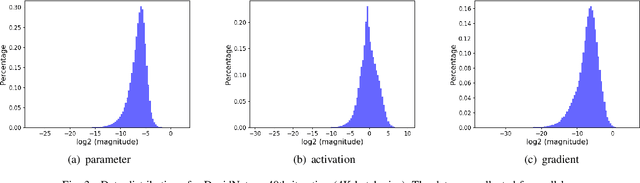
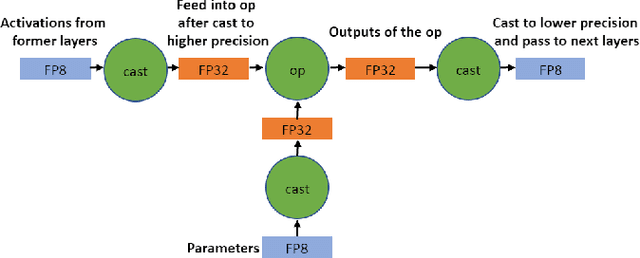
In recent years, large-batch optimization is becoming the key of distributed deep learning. However, large-batch optimization is hard. Straightforwardly porting the code often leads to a significant loss in testing accuracy. As some researchers suggested that large batch optimization leads to a low generalization performance, and they further conjectured that large-batch training needs a higher floating-point precision to achieve a higher generalization performance. To solve this problem, we conduct an open study in this paper. Our target is to find the number of bits that large-batch training needs. To do so, we need a system for customized precision study. However, state-of-the-art systems have some limitations that lower the efficiency of developers and researchers. To solve this problem, we design and implement our own system CPD: A High Performance System for Customized-Precision Distributed DL. In our experiments, our application often loses accuracy if we use a very-low precision (e.g. 8 bits or 4 bits). To solve this problem, we proposed the APS (Auto-Precision-Scaling) algorithm, which is a layer-wise adaptive scheme for gradients shifting. With APS, we are able to make the large-batch training converge with only 4 bits.