 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Semantic Segmentation of Aerial Images Using Patch-based Attention
Paper and Code

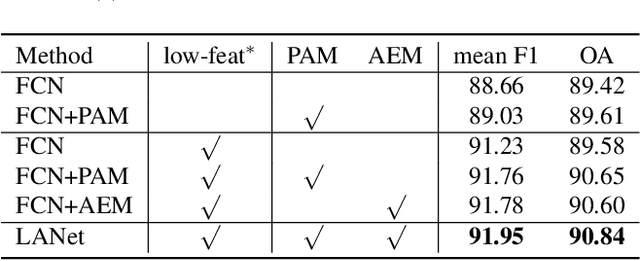
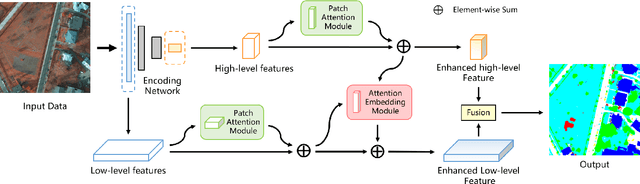

The trade-off between feature representation power and spatial localization accuracy is crucial for the dense classification/semantic segmentation of aerial images. High-level features extracted from the late layers of a neural network are rich in semantic information, yet have blurred spatial details; low-level features extracted from the early layers of a network contain more pixel-level information, but are isolated and noisy. It is therefore difficult to bridge the gap between high and low-level features due to their difference in terms of physical information content and spatial distribution. In this work, we contribute to solve this problem by enhancing the feature representation in two ways. On the one hand, a patch attention module (PAM) is proposed to enhance the embedding of context information based on a patch-wise calculation of local attention. On the other hand, an attention embedding module (AEM) is proposed to enrich the semantic information of low-level features by embedding local focus from high-level features. Both of the proposed modules are light-weight and can be applied to process the extracted features of convolutional neural networks (CNNs). Experiments show that, by integrating the proposed modules into the baseline Fully Convolutional Network (FCN), the resulting local attention network (LANet) greatly improves the performance over the baseline and outperforms other attention based methods on two aerial image datasets.