 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Adaptive Gradient Sparsification for Distributed Deep Learning with Convergence Guarantees
Paper and Code
Nov 21, 2019
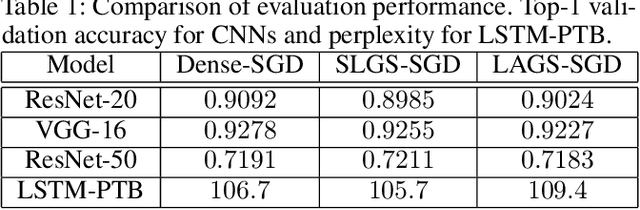
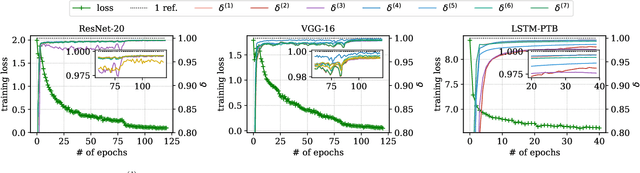
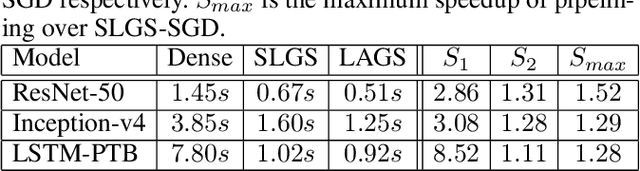
To reduce the long training time of large deep neural network (DNN) models, distributed synchronous stochastic gradient descent (S-SGD) is commonly used on a cluster of workers. However, the speedup brought by multiple workers is limited by the communication overhead. Two approaches, namely pipelining and gradient sparsification, have been separately proposed to alleviate the impact of communication overheads. Yet, the gradient sparsification methods can only initiate the communication after the backpropagation, and hence miss the pipelining opportunity. In this paper, we propose a new distributed optimization method named LAGS-SGD, which combines S-SGD with a novel layer-wise adaptive gradient sparsification (LAGS) scheme. In LAGS-SGD, every worker selects a small set of "significant" gradients from each layer independently whose size can be adaptive to the communication-to-computation ratio of that layer. The layer-wise nature of LAGS-SGD opens the opportunity of overlapping communications with computations, while the adaptive nature of LAGS-SGD makes it flexible to control the communication time. We prove that LAGS-SGD has convergence guarantees and it has the same order of convergence rate as vanilla S-SGD under a weak analytical assumption. Extensive experiments are conducted to verify the analytical assumption and the convergence performance of LAGS-SGD. Experimental results show that LAGS-SGD achieves from around 40\% to 95\% of the maximum benefit of pipelining on a 16-node GPU cluster. Combining the benefit of pipelining and sparsification, the speedup of LAGS-SGD over S-SGD ranges from 2.86$\times$ to 8.52$\times$ on our tested CNN and LSTM models, without losing obvious model accuracy.