 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Curiosity for Efficient Exploration in Reinforcement Learning
Paper and Code
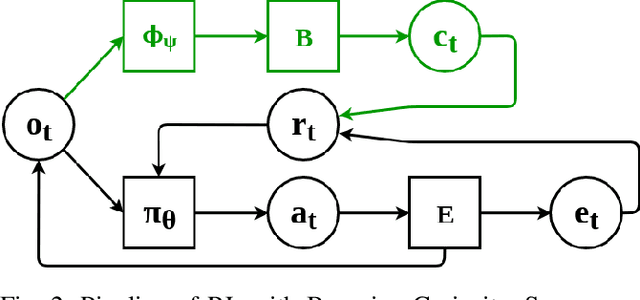
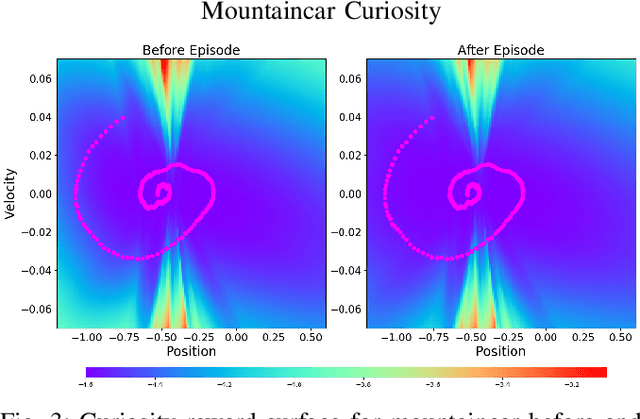
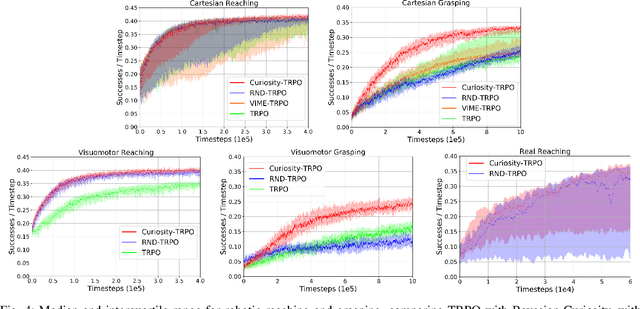
Balancing exploration and exploitation is a fundamental part of reinforcement learning, yet most state-of-the-art algorithms use a naive exploration protocol like $\epsilon$-greedy. This contributes to the problem of high sample complexity, as the algorithm wastes effort by repeatedly visiting parts of the state space that have already been explored. We introduce a novel method based on Bayesian linear regression and latent space embedding to generate an intrinsic reward signal that encourages the learning agent to seek out unexplored parts of the state space. This method is computationally efficient, simple to implement, and can extend any state-of-the-art reinforcement learning algorithm. We evaluate the method on a range of algorithms and challenging control tasks, on both simulated and physical robots, demonstrating how the proposed method can significantly improve sample complexity.