 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Perceptible Backdoors, without the Training Set, via the Maximum Achievable Misclassification Fraction Statistic
Paper and Code
Nov 18, 2019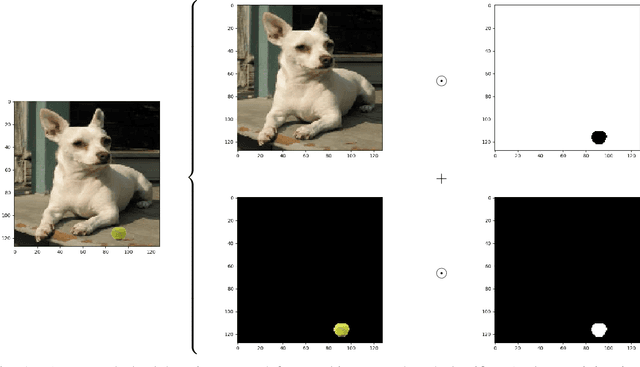

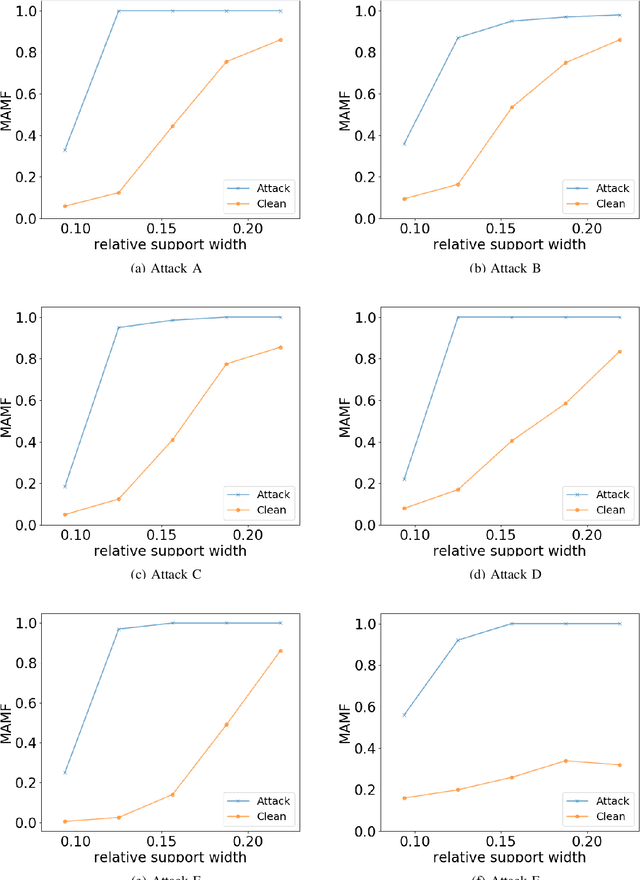
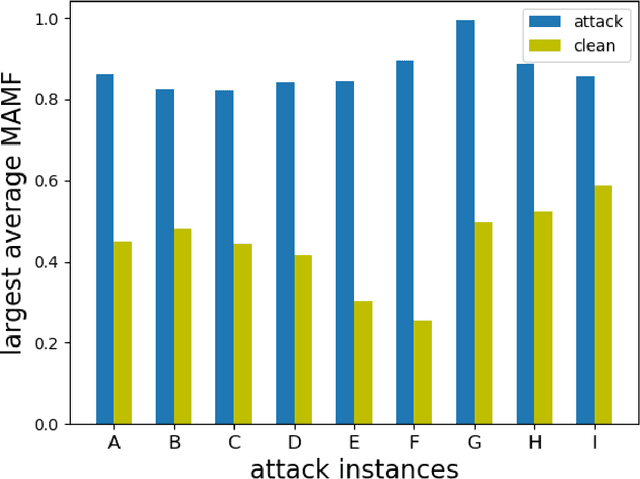
Recently, a special type of data poisoning (DP) attack, known as a backdoor, was proposed. These attacks aimto have a classifier learn to classify to a target class whenever the backdoor pattern is present in a test sample. In thispaper, we address post-training detection of perceptible backdoor patterns in DNN image classifiers, wherein thedefender does not have access to the poisoned training set, but only to the trained classifier itself, as well as to clean(unpoisoned) examples from the classification domain. This problem is challenging since a perceptible backdoorpattern could be any seemingly innocuous object in a scene, and, without the poisoned training set, we have nohint about the actual backdoor pattern used during training. We identify two important properties of perceptiblebackdoor patterns, based upon which we propose a novel detector using the maximum achievable misclassificationfraction (MAMF) statistic. We detect whether the trained DNN has been backdoor-attacked and infer the sourceand target classes used for devising the attack. Our detector, with an easily chosen threshold, is evaluated on fivedatasets, five DNN structures and nine backdoor patterns, and shows strong detection capability. Coupled with animperceptible backdoor detector, our approach helps achieve detection for all evasive backdoors of interest.