 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Making Deep Transfer Learning Never Hurt
Paper and Code
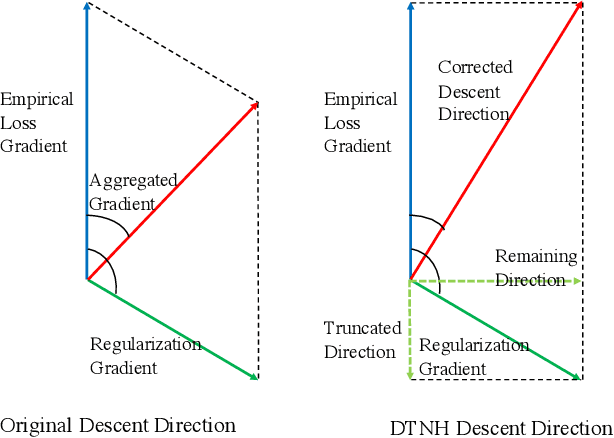
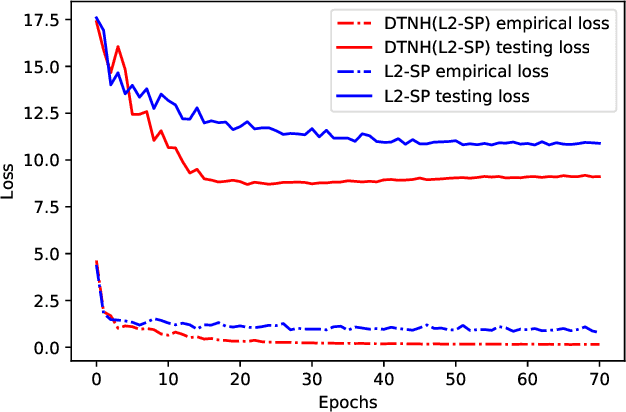
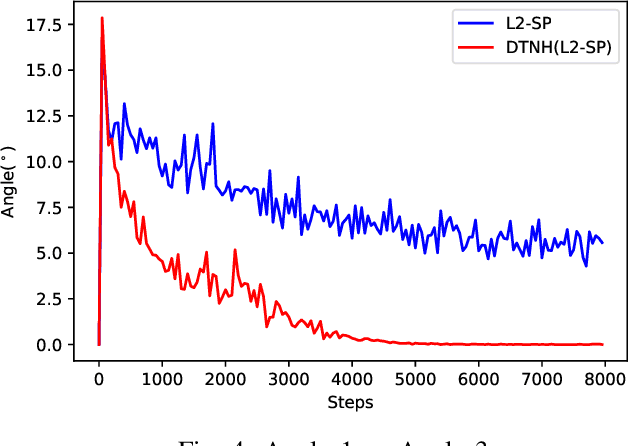
Transfer learning have been frequently used to improve deep neural network training through incorporating weights of pre-trained networks as the starting-point of optimization for regularization. While deep transfer learning can usually boost the performance with better accuracy and faster convergence, transferring weights from inappropriate networks hurts training procedure and may lead to even lower accuracy. In this paper, we consider deep transfer learning as minimizing a linear combination of empirical loss and regularizer based on pre-trained weights, where the regularizer would restrict the training procedure from lowering the empirical loss, with conflicted descent directions (e.g., derivatives). Following the view, we propose a novel strategy making regularization-based Deep Transfer learning Never Hurt (DTNH) that, for each iteration of training procedure, computes the derivatives of the two terms separately, then re-estimates a new descent direction that does not hurt the empirical loss minimization while preserving the regularization affects from the pre-trained weights. Extensive experiments have been done using common transfer learning regularizers, such as L2-SP and knowledge distillation, on top of a wide range of deep transfer learning benchmarks including Caltech, MIT indoor 67, CIFAR-10 and ImageNet. The empirical results show that the proposed descent direction estimation strategy DTNH can always improve the performance of deep transfer learning tasks based on all above regularizers, even when transferring pre-trained weights from inappropriate networks. All in all, DTNH strategy can improve state-of-the-art regularizers in all cases with 0.1%--7% higher accuracy in all experiments.