 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Networks for Multi-Label Learning
Paper and Code
Nov 17, 2019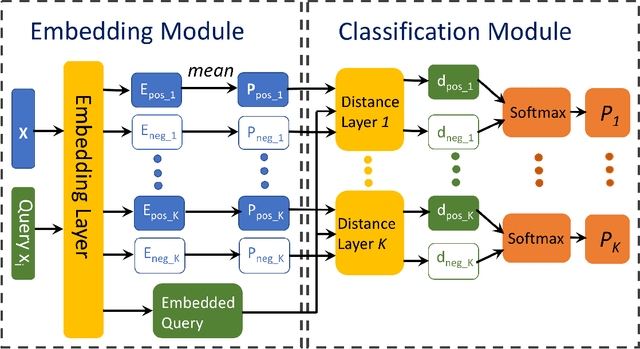
We propose to address multi-label learning by jointly estimating the distribution of positive and negative instances for all labels. By a shared mapping function, each label's positive and negative instances are mapped into a new space forming a mixture distribution of two components (positive and negative). Due to the dependency among labels, positive instances are mapped close if they share common labels, while positive and negative embeddings of the same label are pushed away. The distribution is learned in the new space, and thus well presents both the distance between instances in their original feature space and their common membership w.r.t. different categories. By measuring the density function values, new instances mapped to the new space can easily identify their membership to possible multiple categories. We use neural networks for learning the mapping function and use the expectations of the positive and negative embedding as prototypes of the positive and negative components for each label, respectively. Therefore, we name our proposed method PNML (prototypical networks for multi-label learning). Extensive experiments verify that PNML significantly outperforms the state-of-the-arts.