 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Large-margin Softmax Loss for Speaker Diarisation
Paper and Code
Nov 10, 2019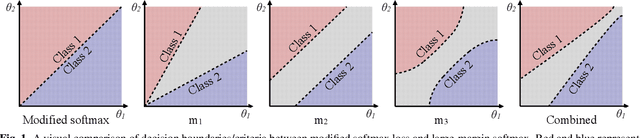

Speaker diarisation systems nowadays use embeddings generated from speech segments in a bottleneck layer, which are needed to be discriminative for unseen speakers. It is well-known that large-margin training can improve the generalisation ability to unseen data, and its use in such open-set problems has been widespread. Therefore, this paper introduces a general approach to the large-margin softmax loss without any approximations to improve the quality of speaker embeddings for diarisation. Furthermore, a novel and simple way to stabilise training, when large-margin softmax is used, is proposed. Finally, to combat the effect of overlapping speech, different training margins are used to reduce the negative effect overlapping speech has on creating discriminative embeddings. Experiments on the AMI meeting corpus show that the use of large-margin softmax significantly improves the speaker error rate (SER). By using all hyper parameters of the loss in a unified way, further improvements were achieved which reached a relative SER reduction of 24.6% over the baseline. However, by training overlapping and single speaker speech samples with different margins, the best result was achieved, giving overall a 29.5% SER reduction relative to the baseline.