 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Multi-Label Crowd Consensus
Paper and Code
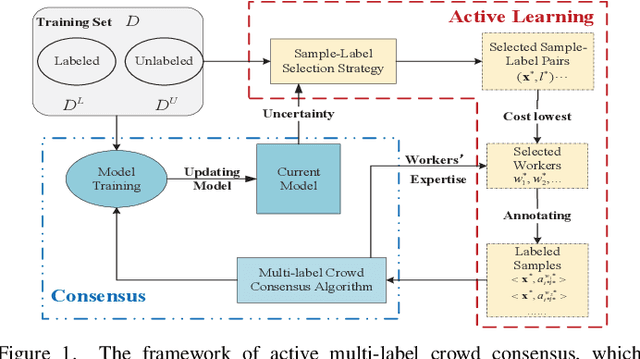
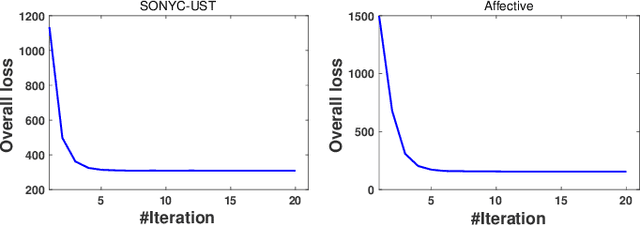
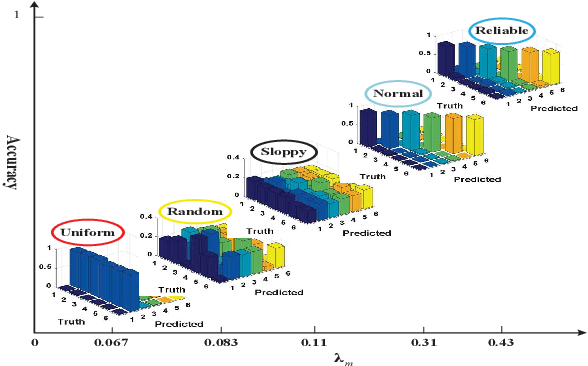
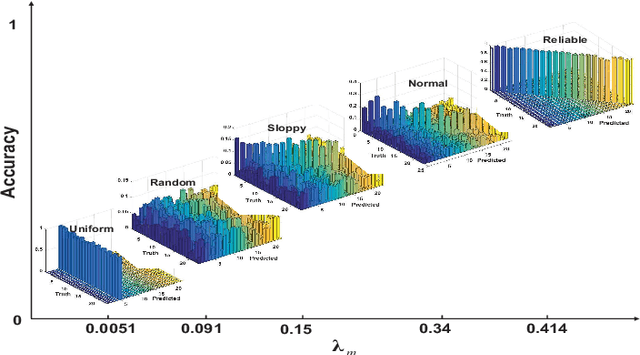
Crowdsourcing is an economic and efficient strategy aimed at collecting annotations of data through an online platform. Crowd workers with different expertise are paid for their service, and the task requester usually has a limited budget. How to collect reliable annotations for multi-label data and how to compute the consensus within budget is an interesting and challenging, but rarely studied, problem. In this paper, we propose a novel approach to accomplish Active Multi-label Crowd Consensus (AMCC). AMCC accounts for the commonality and individuality of workers, and assumes that workers can be organized into different groups. Each group includes a set of workers who share a similar annotation behavior and label correlations. To achieve an effective multi-label consensus, AMCC models workers' annotations via a linear combination of commonality and individuality, and reduces the impact of unreliable workers by assigning smaller weights to the group. To collect reliable annotations with reduced cost, AMCC introduces an active crowdsourcing learning strategy that selects sample-label-worker triplets. In a triplet, the selected sample and label are the most informative for the consensus model, and the selected worker can reliably annotate the sample with low cost. Our experimental results on multi-label datasets demonstrate the advantages of AMCC over state-of-the-art solutions on computing crowd consensus and on reducing the budget by choosing cost-effective triplets.