 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-invariant Affective Representation Learning via Adversarial Training
Paper and Code
Nov 04, 2019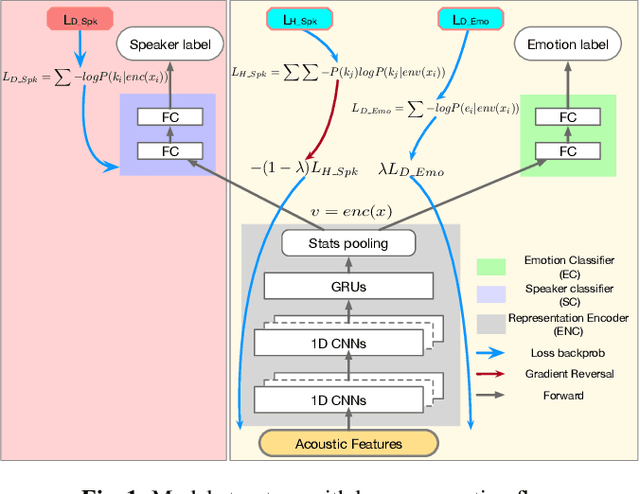
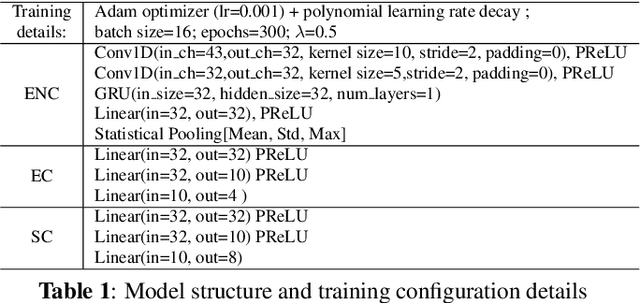
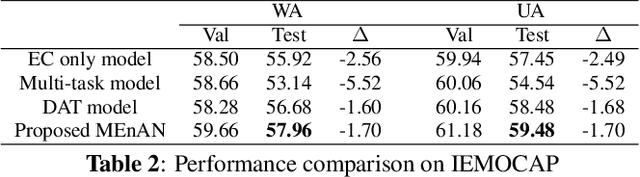
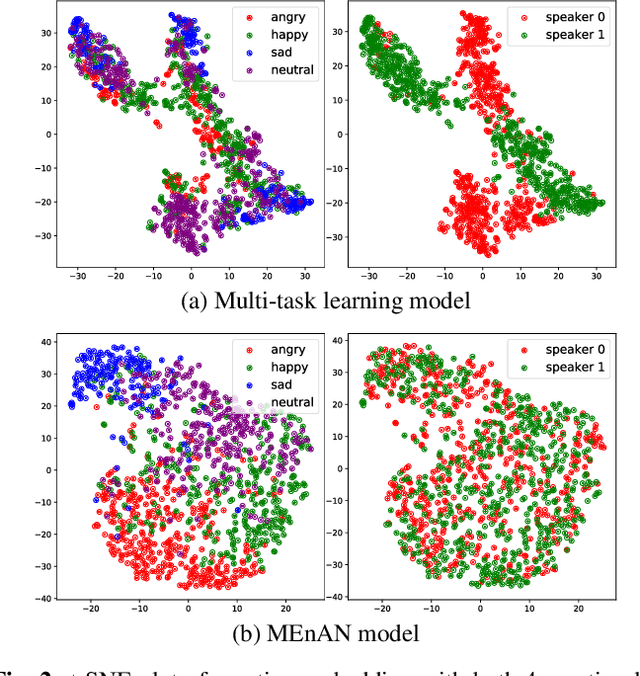
Representation learning for speech emotion recognition is challenging due to labeled data sparsity issue and lack of gold standard references. In addition, there is much variability from input speech signals, human subjective perception of the signals and emotion label ambiguity. In this paper, we propose a machine learning framework to obtain speech emotion representations by limiting the effect of speaker variability in the speech signals. Specifically, we propose to disentangle the speaker characteristics from emotion through an adversarial training network in order to better represent emotion. Our method combines the gradient reversal technique with an entropy loss function to remove such speaker information. Our approach is evaluated on both IEMOCAP and CMU-MOSEI datasets. We show that our method improves speech emotion classification and increases generalization to unseen speakers.