 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond-Order Group Influence Functions for Black-Box Predictions
Paper and Code
Nov 01, 2019
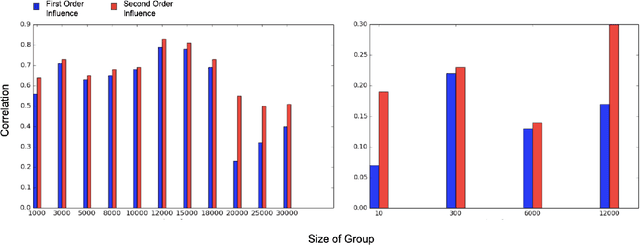
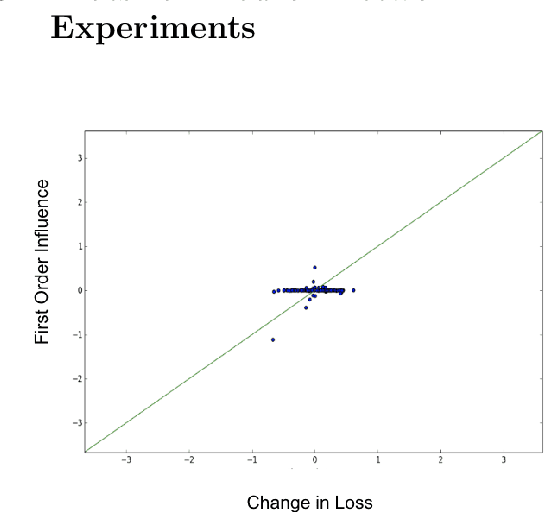
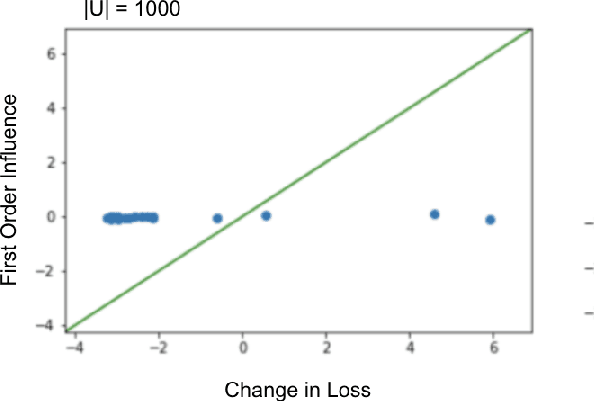
With the rapid adoption of machine learning systems in sensitive applications, there is an increasing need to make black-box models explainable. Often we want to identify an influential group of training samples in a particular test prediction. Existing influence functions tackle this problem by using first-order approximations of the effect of removing a sample from the training set on model parameters. To compute the influence of a group of training samples (rather than an individual point) in model predictions, the change in optimal model parameters after removing that group from the training set can be large. Thus, in such cases, the first-order approximation can be loose. In this paper, we address this issue and propose second-order influence functions for identifying influential groups in test-time predictions. For linear models and across different sizes of groups, we show that using the proposed second-order influence function improves the correlation between the computed influence values and the ground truth ones. For nonlinear models based on neural networks, we empirically show that none of the existing first-order and the proposed second-order influence functions provide proper estimates of the ground-truth influences over all training samples. We empirically study this phenomenon by decomposing the influence values over contributions from different eigenvectors of the Hessian of the trained model.