 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Video-to-Video Synthesis
Paper and Code
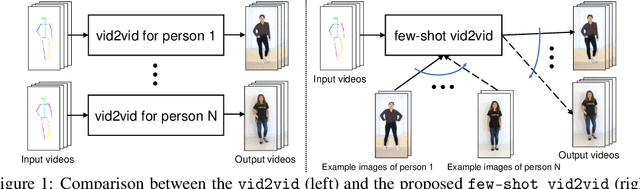
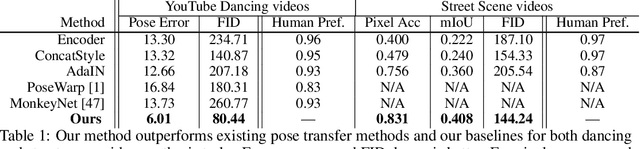
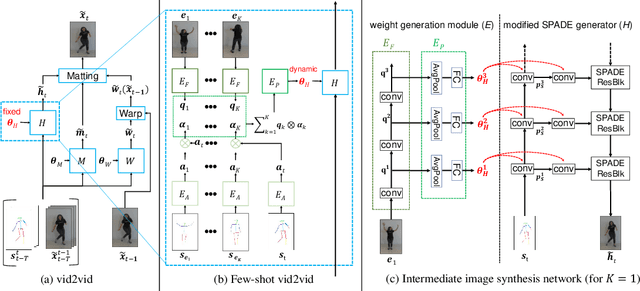

Video-to-video synthesis (vid2vid) aims at converting an input semantic video, such as videos of human poses or segmentation masks, to an output photorealistic video. While the state-of-the-art of vid2vid has advanced significantly, existing approaches share two major limitations. First, they are data-hungry. Numerous images of a target human subject or a scene are required for training. Second, a learned model has limited generalization capability. A pose-to-human vid2vid model can only synthesize poses of the single person in the training set. It does not generalize to other humans that are not in the training set. To address the limitations, we propose a few-shot vid2vid framework, which learns to synthesize videos of previously unseen subjects or scenes by leveraging few example images of the target at test time. Our model achieves this few-shot generalization capability via a novel network weight generation module utilizing an attention mechanism. We conduct extensive experimental validations with comparisons to strong baselines using several large-scale video datasets including human-dancing videos, talking-head videos, and street-scene videos. The experimental results verify the effectiveness of the proposed framework in addressing the two limitations of existing vid2vid approaches.